
Business Intelligence In One Weekend
Version 1.2.1, 2019-02-04
Copyright 2019-2024 Iyad Horani. All rights reserved.

Overview
How do you choose a Business Intelligence (BI) solution for your company? Do you search for reviews about a particular tool? Do you perform a Tableau vs Power BI search? Aside from the feature lists and rating, how do you know that Tableau is the better solution for your business?
If someone is familiar with BI technologies, then they'd first understand the business type, the intended outcome of the BI tool, and the current technology stack used by the business. Those questions make figuring out the right BI solution an easy task, because this person posses the required knowledge of the BI technologies core components, features and usability features. If you're not that person, then I would a guess that those "vs" searches didn't help out in giving you confidence that BI tool X is the right choice for your business.
If you're not that person who's familiar with BI technologies, but you have the interest and desire to start using Business Intelligence tools to add to your business, then this guide for you. We wrote this guide to be as complete as possible to answer all your questions about BI, be it price, salary expectations for Data Analyst, and even features.
However, rather than listing different tools and features, we took a different approach. This guide is educational, and it's meant to take you from zero to hero in understanding everything you need to know about BI including:
what is a BI technology,
how do you use those features,
how those features differ from one solution to another,
how will it affect your business,
what else do you need to purchase along with a BI solution,
Who else do you need to hire, or do you need to hire anyone?
Which solution can you pick up today and know that it gives your business the results you need today?
And many more answers.
This guide takes you on a journey of becoming knowledgeable about BI. We're not aiming to make you an expert and implement one your self, unfortunately getting you to this point requires 20x more the size of this guide. Instead, this knowledge helps you form a more educated and informed decision whether your business needs a BI solution today, what is involved in deciding to implement a BI solution, and more importantly, how much is it all going to cost your business and will it have the required ROI.
There is a lot to be excited about BI and the promises a BI delivers to a business. We know this because Forbes states that insights-driven companies are on track to earn $1.8 trillion by 2021. Forbes We also know that BI can be notoriously complex and expensive to implement, often taking six months or more. Which associate BI with fear for many companies. Should a company invest a considerable sum on implementation and new hire, wait for six months before seeing a positive effect on the company's bottom line? We understand the dilemma and the risks businesses faces when they choose to adopt BI without knowledge of what BI involves. You can mitigate this risk by equipping yourself with just enough knowledge and framework of a proper BI implementation.
The ideas, concepts and principles in this guide are logical and straightforward to understand and implement. Technical concepts are built upon chapter by chapter and are introduced solely because of their importance to the overall implementation solution.
Today, there's a BI tool for every business size and challenge. Tools that are smarter, and solutions that are accessible than it used to be 15 years ago. The BI market which is expected to grow to a $29.48 billion by 2022. Reuters
For some this means more "vs" searches to perform, for those reading this guide, they'll know if a BI tool is the right one for their business just by skimming through the features list.
We hope you enjoy reading this guide as much as it did for us writing it. We're confident we'll answer all your all your questions about Business Intelligence.
TABLE OF CONTENTS
- Ch.1
What is Business Intelligence - Ch.2
Business Intelligence Functions - Ch2.1 Reports and Widgets
- Ch2.2 Dashboards and Data Walls
- Ch2.3 Drillthrough
- Ch2.4 Alerts and Scheduled Reports
- Ch2.5 Analytics
- Ch2.6 Augmented Analytics
- Ch.3
Practical BI Use Cases - Ch3.1 Performance Marketing
- Ch3.2 Process Optimisations
- Ch.4
Business Intelligence Components - Ch4.1 Data Sources
- Ch4.2 ETL
- Ch4.3 Connectors
- Ch4.4 Data Warehouse
- Ch4.5 Data Preparation
- Ch.5
Business Intelligence Skills - Ch5.1 Development
- Ch5.2 Analytics
- Ch.6
Business Intelligence Helpers - Ch6.1 ETL Helpers
- Ch6.2 Data Preparation Helpers
- Ch6.2.1 Paxata
- Ch6.2.2 Tableau Prep
- Ch.7
Business Intelligence Tools - Ch7.1 Self-Service BI vs Traditional
- Ch7.2 DataBox
- Ch7.3 Tableau
- Ch7.4 Microsoft Power BI
- Ch7.5 Infor(Birst)
- Ch7.6 Salesforce Einstein Analytics
- Ch7.7 Gartner MQ in Analytics and BI
- Ch.8
Conclusion

Ch1. What is Business Intelligence
The term Business Intelligence (BI) refers to technologies, applications and practices for the collection, integration, analysis, and presentation of business information. This chapter will introduce the BI technologies, the types of intelligence a BI provides businesses and the type of questions a company can answer through a BI solution.
Business Intelligence (BI) is a technology-driven process that leverages data a company already have to convert knowledge into informed actions. The process analyses a company data and presents actionable information to help executives, managers, and other business end users make informed decisions and measure the health of the business.
BI can be used by companies to support a wide range of business decisions ranging from operational to strategic. Fundamental operating choices include product positioning or pricing. Strategic business decisions involve priorities, goals, and directions at the broadest level. In all cases, BI is most effective when it combines data derived from the market in which a company operates (external data) with data from company sources internal to the business such as financial and operations data (internal data). When combined, external and internal data can provide a complete picture which, in effect, creates an “intelligence” that cannot derive from any single set of data.
The ability to combine data source is what sets BI apart from regular reporting and analysis tools found in modern cloud applications. One example of this is Google Analytics (GA). GA provides a company with a comprehensive activity view of all website visitors. GA also allows linking to other Google products inside of GA (AdSense, Google Ads, Google Search Console, and even Google Play). However popular, Google still offers Data Studio. A stand-alone BI tool that imports data from GA, Google products and other external sources. So what's the added value of Data Studio over GA?
Let's say we wanted to know the different channels responsible for the sale of 50 Databox online course this month. In GA we could identify that 50% of the traffic originated from an organic source. Organic means a search made on Google and the prospect opted to click on our website. Knowing the search terms responsible for the conversion would allow us to generate content that targets those keywords, which eventually have the potential to increase our conversion rate from organic search and decrease our ad spend. However, GA does not tell us which organic terms are responsible for the conversion. At this point, we can check the acquisition tab and look through the search console panel to analyse the organic search traffic. The report gives us a list of all search terms that resulted in having IRONIC3D appear as a search result, and which terms resulted in clicks to our website. Useful as it is, there is still a wide gap between organic traffic and knowing which terms were responsible for the conversions. This knowledge is the difference between having several fishing nets in multiple locations versus a single fishing net in a specific bay. With Google Data Studio we can import the raw data from both platforms and perform analysis to determine to a certain degree which search terms were responsible for the conversions.
So what are some examples of intelligence a company can have with BI tools:
Suppose you run an online store selling designer shoes. Your main channels for acquiring sales are through Google AdWords, Facebook, Instagram, Newsletters and organic search. Each channel is a separate application with its analytics interface, so you can check from newsletter application how many people clicked on your email link, your accounting software tells you who bought the items, which at this should be enough and roll out that the Newsletter as the reason for the purchase. However, looking at data from silo sources doesn’t give you the purchase lifecycle, and more importantly, what was the last conversion point responsible for the purchase:
Did person X click the link and went straight to purchase the shoes?
Alternatively, did person X click on the email link, decided to take a couple of days to think about it, saw your advertising on Instagram, read the positive comments and then decided to purchase?
Intelligence can also happen within a single application, Let’s take Insightly as an example. Insightly is a business CRM with many sophisticated capabilities. One feature in particular that we find extremely useful at IRONIC3D is the relationships feature. Relationships allow Insightly to links contacts together (directional linking, both forward and reverse relations), as well as linking companies together. So you can define a new relationship of a parent company, and it's subsidiary companies, or a coach and a client relationship, parent and child relationship, marital relationships, friendships as well as ex-employments. These types of relationships are beneficial if your business depends on cultivating relationships with your clients. Unfortunately, there isn’t an easy way to visualise all of your contacts and all the associated relationships, in fact, you’ll have to check each contact individually to see what type of a relationship that contact has. You cannot even list and segment those relationships to see who’s who, for example, you cannot list all influencers or the most active influencer. Unless Insightly builds this interface for you, there is no way to get this type of reports. (Note: Insightly introduced a visual map for contacts in its recent update. This feature is for Enterprise subscribers only). With BI however you can extend that reporting capability and build as many reporting views for relationships as you deem fit. You don’t have to wait for the vendor to update their software, nor you need to hire a developer to extend the system.
BI can also be used to extend and implement your business roles. A typical example of this is commission calculation. If your product invoicing depends on multiple delivery dates, then most probably your finance team is performing that calculation using Excel or Google Sheets, however, performing commission percentage is easily accomplished with a BI tool, it's also happening in real-time.
Lastly, you can BI as an early notification or an alarm system for the most critical business metrics. Not only that, but it can also tell you where exactly you need to look. An example of this is a services sales. Sales is a result of various marketing and sales steps, so if you’re selling a service and have a specific target for each month, it’s not very useful to know that you won't be meeting this months sales target. On its own, this doesn’t tell you what needs to happen to meet the sales target. With a BI tool, you can break the marketing and sales process and assign targets for each step, and assign a target, or a threshold, for each step. Thus, if one of the steps is below the threshold, you’ll be notified about that step.
Simply put, BI is required to operate a business. It provides an interface that empowers decision makers to discover answers to specific questions that affect business performance.
With BI we typically examine data to look for three main areas of interest:
1. Aggregations, looking at grand totals, for example. How much online courses sold last year? Beyond just simple totals is the ability to slice and dice, as it is called, breaking down totals into smaller pieces. How much online courses were sold by a state? For each state, how much was sold by subject? Business intelligence tools provide the ability to break these totals down into smaller pieces for comparison and analytics purposes.
2. Trends, knowing the current totals are significant but just as important is knowing how those totals change over time. Knowing these changes can help you decide how well a product is doing. Had the sales for a specific demographic of online courses increased or decreased over the last year? Knowing this can help you decide whether to place a course on sale, increase the price, or take it off the market altogether.
3. Correlations, tools such as data mining and machine learning are used to find correlations that might not be obvious. A favourite story among BI enthusiasts is the correlations uncovered by a major store chain between diapers and beer. When data mining was applied, they found a strong link between the sales of the two. When beer sells tended to peak, so made the diaper sales. Salespeople surmised that individuals on their way home to pick up diapers would also grab some beer. As a result, the diaper sections and beer sections moved close to each other further increase sales, all because of the power of correlations.
A BI tool allows you to explore those areas of interest in the form of questions, you ask your data questions, and your data answers through a visual response. The type of questions asked on data can be categorised into How, Why, and What.
How questions the state of the business. At the current time or in the past.
How are we doing on project deliveries and are we on time?
How did sales person x perform last month?
Why questions are to find the reason behind a particular business result. A result that happened already. What Why tries to find is a relationship between data that causes changes.
Why are current sales down this month?
Why is product x not performing in this period compared to the previous period?
What questions focuses mostly on the future of the company, past time, but it’s predominantly used for future time states.
What are our current profit margins look?
What will our profit margin look like in 3 months time?
What did we deliver this past month?

A BI tool allows for grouping of those question into one or more views, which provides continuous real-time answers to key-business metric, and accessible to all business parts. The grouping ensures teams are always aware of the company immediate, short or long-term goals, as well the drivers required to reach those goals.
Finding a single BI application that answers all questions of How, Why and What of business are uncommon. Most BI applications are specialised and deal mainly with the current business state and past state. The future state requires additional specialised software that either work alone, or side-by-side with a given BI application.
As such, the first differentiation factor between BI application is how versatile a BI application can deal with current, past and future states of business. There are BI applications that are specific to aggregation, others allow for trend, and a few allow for correlations as well. Finding the right BI tool depends on the business area of interests a BI tool needs to examine, as well as the type of questions the business needs to answer.
Is your business interested in a BI application that wants answers to the current state, past state or future state?
Is your business interest in data is to have answers about the Why, the How, or the What?
Where do these questions fall into, are they in the immediate business needs, short-term needs, or a strategy?
Which one is more important for you now?
Also, BI technologies provide historical, current and predictive views of business operations. Typical functions of BI technologies include:
Reporting
Analytics
Data mining
Process mining
Complex event processing
Business performance management
Benchmarking
Predictive analytics.
Having a clear understanding of where your business needs lies and the type of questions your company is looking for is the first step to narrowing down the best BI solution for your company.
BI technologies are verstile. providing historical, current and predictive views of business operations. Typical functions of BI technologies include:
Reporting
Analytics
Data mining
Process mining
Complex event processing
Business performance management
Benchmarking
Predictive analytics.
Having a clear understanding of where your business needs are, and the type of questions your company is looking for is the first step to narrowing down the best BI solution for your company.
Ch2. Business Intelligence Functions
BI functions are the first thing people read when researching a BI tool, so it makes sense for us to start exploring them. This chapter will discuss each function and explain what they are and how are they used in real-world scenarios. We'll also explore the weight each function holds on the BI application pricing.
- Ch2.1 Reports and Widgets
- Ch2.2 Dashboards and Data Walls
- Ch2.3 Drillthrough
- Ch2.4 Alerts and Scheduled Reports
- Ch2.5 Analytics
- Ch2.6 Augmented Analytics
Reporting is the means of displaying data inside a BI tool in a visual manner. A report represents a view that is of interest for your business. In other words, it presents the results of a question. Typically a BI tool will have an arsenal of visuals to show the result in any number of ways.
Reports are sometimes called widgets or tiles, the naming between BI tools might differ, but the functionality is the same across BI tools. The only difference between each BI tool is the levels of customisation that are available to you.
On a basic level, a report should display the dimensions and measures along with a time series, as well enough customisation options to the look and feel of the visual (e.g. colours, header names, font, size). Advanced reports allow for layering of multiple data on the same visual for comparison, or even analytical data such as trend lines. Some specialised BI tool will also allow for a deeper level of customisation to the look and feel of the report (Tableau is one of those tools, it position itself as a Visualisation Tool rather than a BI tool because of the many customisations it offers)
We've mentioned that a report displays data which include dimensions, measures and time-series, let's give a brief definition of what those means.
Dimension is an attribute that categorises your data. So if you’re looking for sales by country, the country is a dimension in this case. Dimensions are also a way to navigate the data to get a different view. For example, you might want to see product performance over time, then get a different point of view and see regional performance over time. These categories provide perspectives which are called dimensions.
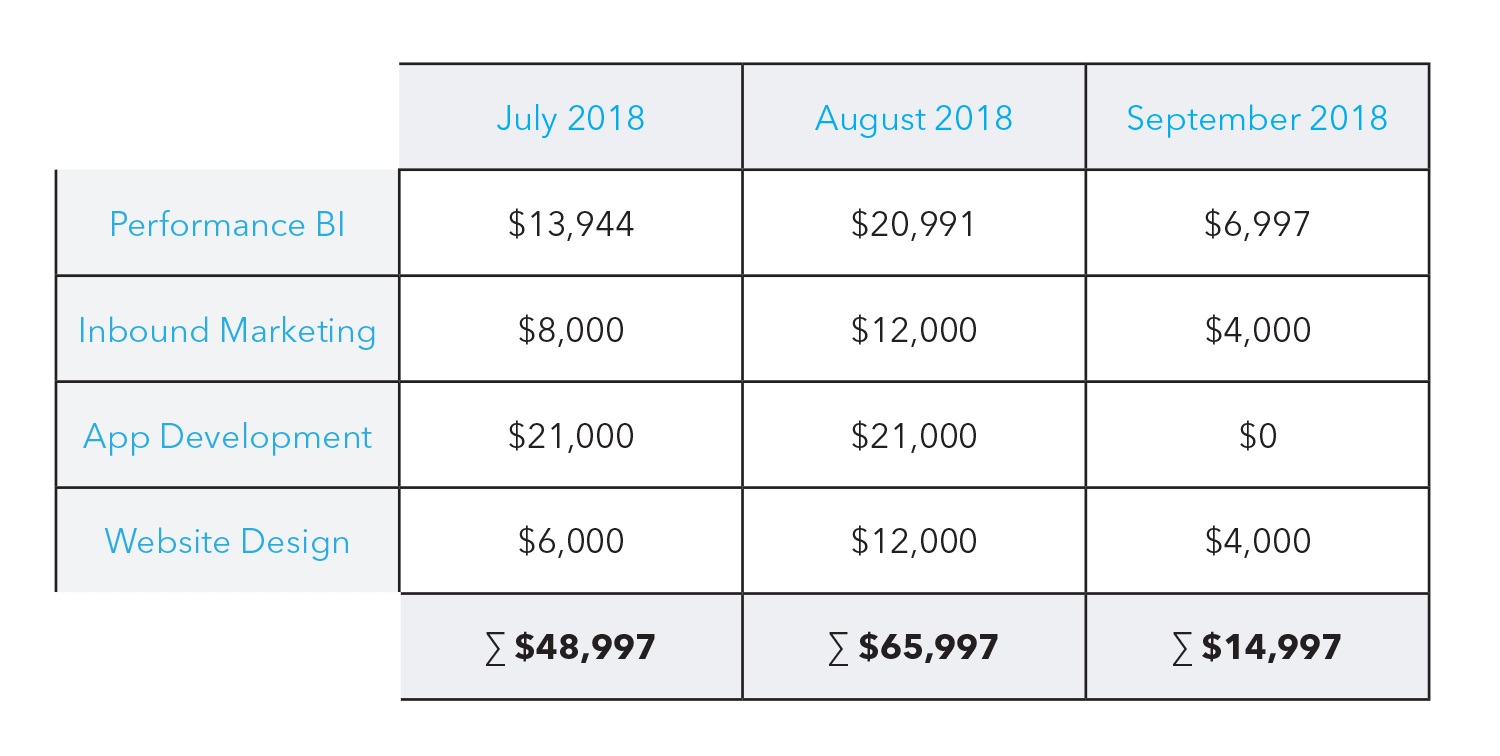

So dimensions can be anything which can consistently categorise your data, and provide you with a better point of view.

A measure is a numerical value that quantifies the data set you are digging into to understand better. They also provide meaning to your dimensions. So in the example of sales by regions, the sale value is a measure.
A collection of measures of the same type can be summed, averaged, floored or apply an arithmetic operator to aggregate them.
Metric is not the same as a measure. A measure is a number derived from taking a measurement. A metric, however, is a calculation between two or more measures.
Calculated Metrics are user-defined metrics that are computed from existing metrics and drive more relevant analyses and enable greater actionability without leaving the product. For example, profit is a calculated metric that is calculated from the Revenue metric, Operating costs metric and any other liabilities to the business.
Time-Series is how you analyse your measures by date. The usual time series is today, yesterday, this week, last week, week to date, this month, last month, month to date, this financial year, last fiscal year, this quarter, etc.
Time series is an especially important feature, often overlooked. Depending on where your company is, a proper BI tool should allow creating custom time series. For instance, if your business operates in Australia, you would want to measure your revenue based on AU financial year, which starts from 1st of July till the 30th of June. If a BI tool doesn't allow for custom time series, then your fiscal year will default to 1st of Jan till the 31st of Dec.
Reports can either be static or dynamic. With static reports, the resulting data displayed doesn't allow the end user to change its content. So one cannot perform filtering on the data to show different time series or include additional data in the form of check-boxes or drop downs menus. Static reports are useful to generate a final report or daily, weekly, or monthly reports that are delivered to a person or a department by email.
Dynamics reports allow for a report to be filtered and show different results. An example of this would be to filter product sales by financial year, region and category.
All BI tools will provide a similar set of standard reports. Report widgets are eye candy and a huge selling point in the promotion of any BI tool. However useful and visually appealing they may be, reporting widgets don’t have a massive influence on the overall pricing of a BI tool. Some BI tools might include additional functionalities to the report widgets by the following three two points:
Can a report have visual filters presented alongside the report, in the form of the input area, drop-downs, check-boxes?
How customisable is a report? Does the BI tool give you access to a scripted interface to manipulate the underlying code behind a visual? Or can you write your custom visual?
Can the BI tool allow for the business or a 3rd party vendor to create custom widgets (e.g. Power BI enables downloading of custom widgets from an online marketplace)
Embedded filters are a usability feature that is of importance, as it’s directly related to workflow and how to make the final reports accessible and usable by the end user. So look beyond the pretty reports and instead check the degree of report interaction.
Extending the widget library with 3rd party widgets is useful however it should not be a deciding factor for choosing a BI tool. There reason all BI tools ship with the same standard reports is because those visuals are widely used, and are considered the standard way to represent data. If your reporting needs are particular, find the tool that will provide those reporting visual out of the box.
- The exception to this rule is the Geo Mapping BI tools (e.g. CARTO or ArcGIS from Esri). These tools are specific for displaying geolocation data, so the map is at the centre of the display, showing all reports on top of the geo-map.
Reports or Widgets do play a pivotal role in the final pricing of a BI tool, not on features, but instead, on the licensing model. In such cases, pricing is on the overall reports that that is available to a single license or account. More tiles will increase the monthly cost of the license cost.
A dashboard is a collection of reports, mostly similar, placed alongside one another on the same page. Dashboards main function is to tell a story at a glance.
Dashboards are another standard feature in BI and are comparable between applications, the difference in dashboards between BI tools is with the usage which can be any one of the following:

1) Multiple dashboards that you navigate from one to another like an image gallery, also known as a Data Wall.
2) One main dashboard that contains several reports, each report links to a Report View, the report view is a page with several related reports.
3) Drillthrough dashboards which allow for inter-linking and hierarchy between dashboards.
Those types of dashboards differ in usability as well. Data Wall dashboards can only filter the whole view with a date filter, so picking Today filters all reports on the dashboard to display today's data. Report Views, on the other hand, don't allow for the filter to be implemented on the main dashboard, while the report view itself can filter with selector common to the reports, be it a date filter, a name filter or a product filter. The Drillthrough dashboards are much more customisable since each view is a dashboard, with filters embedded in any dashboard.
Dashboard functionality ties directly to the type of BI tool, SSIB tends to offer Data Walls and Report Views, while traditional BI tools provide Drillthrough dashboards.
There are many design patterns for grouping and assembling dashboards in a BI tool. The most common of those is the Value Based Design.
Regardless of the BI type, there needs to be a logic in designing BI dashboards or report views, or else you risk having a highly nonfunctional BI dashboard that is of no use to anyone. To design a functional dashboard you need to choose a design pattern. The one we find most natural for a business is a Results-Based Design.
Results-Based Design
A results-based design assembles data from the bottom up, with the topmost level being the Key Results Indicators (KRI), one level below is the Key Performance Indicators (KPI). KPI’s are the drivers for the KRI’s. One level down is the Action Points responsible for each KPI, followed by the User Roles, and finally, the underlying data and decisions data.

Once the dimensions, measures, metrics assembled in a Value-Based Design map, we group the reports into several dashboards broken down in the following logic:
The Three Stages of a Results-Based Design

1- Display - Are we ok?
This dashboard is the first dashboard the business unit sees. It hosts all of the KRI’s and the Drivers to give the end user an overall health check on the business.
2- Diagnose - Why?
The Diagnosis pages enable heavy-duty analysis, usually assembled in 2 or more dashboards. Also, it’s where real analysis and diagnosis occurs. The goal of each diagnostic dashboard is to enable diagnosis of issues in a manner that leads to action.
The reports found within the diagnostic dashboards show the interaction of drivers, KRI's and action points with a with the use of filters.
Generally, Diagnosis pages are organised by either:
KRI Drivers (e.g. Receivables, Deal Size, Close Rate)
Key Action Points (e.g. Products, Channels, Locations)
3- Decide - What to do?
The decide dashboards are detail pages which enable users to take finite actions to improve KRI and KRI drivers. These dashboards are where most analysis ends up, with a list of specific items on which to take action as filtered by the analysis performed on the Diagnosis pages.

Dashboards functionality have a good impact on the BI application price because it determines the functionality and usage of the BI tool. To make it a point of differentiation between similar BI tool, vendors include Dashboard as part of the licensing model as following:
Number of Dashboards: How many dashboards are available for each account and price tier?
Security: Can you set permissions to assign specific dashboards to individuals or departments?
Embeds: Can a dashboard be inserted to a website or another platform?
An embedded live report from Microsoft Power BI
Dashboards are meant to give the user a complete picture for the health of the business at a glance. Simplicity and concise reports are critical to an excellent Dashboard design. Dashboard features such as embedded filters, drill through, security, and dashboard integrates onto a website are part of the business case, which needs researching at the beginning of the project.
If the BI tool allows for the creation of hierarchies, then you setup drill through (or Drill-in) paths which allows you to drill down from one report to another to reveal additional details. For example, you might have a visualisation that looks at Olympic medal count by a hierarchy made up of sport, discipline, and event. By default, the visualisation would show medal count by sport (e.g. gymnastics, skiing, aquatics). However, because it has a hierarchy, selecting one of the visual elements (such as a bar, line, or bubble), would display an increasingly more-detailed picture. Select the aquatics element to see data for swimming, diving, and water polo. Select the diving element to see details for the springboard, platform, and synchronised diving events.
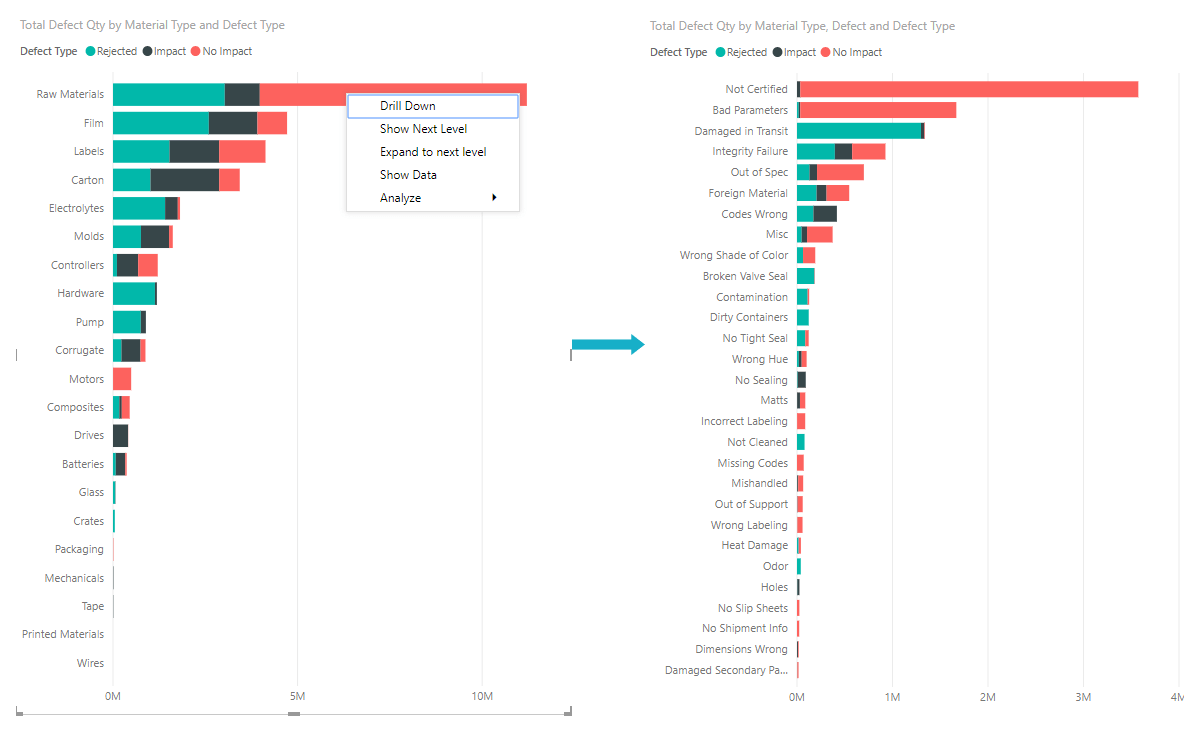
In some instances, Drill-ins can be a link between two separate reports that moves the user from one dashboard to another filtered dashboard specific to the selection made in the previous one.

Drill-ins are an analysis helper feature, as it simplifies the steps and time required to Drill-in to the source of why the data is showing the way it is. As such Drill-in and Drill-through are not available in many SSBI tools, especially the Data Walls BI tools, instead its included in advanced SSIB tolls and well as traditional BI tools.
When evaluating a BI tool get a firm understanding of how the final output is used in the business and by which department, and if drill-ins is a core requirement for the company.
There is an embarrassing about BI regardless of the solution you end up choosing for your company, and that is despite your best efforts, most of the people in the company end up not using the BI application, either entirely or occasionally.
There is a human psychology aspect of how people process information differently from one another, from left brain versus right brain, creative vs analytical, visual versus auditory, convergent versus divergent thinking. These factors play an essential role in the implementation of a BI tool within a business and need to be addressed and accounted for early in the process. The truth of the matter is, BI is implemented by analytical people, which makes some BI implementations overwhelming challenging to discern on a daily basis beyond the people who designed it.
Giving the keys to the BI tool implementations to every department head or team leader to design their measures, reports and dashboards is not the solution. In one instance this was tested, and the manager ended up creating several dashboards, each dashboard having multiple reports with 60+ columns in each. No one in the team was able to read it or use it, not even the manager who created it used it.
Fortunately, this is a constant problem every BI vendor faces. So BI vendors came up with a myriad of clever solutions to increase the retention rate of BI usages in a company. Here are the most popular solutions:
1. Scheduled Reports
Scheduled reports are a summarised report. These reports provides a view to a certain situation. Some example of scheduled reports are:
Fulfillment lists
Delayed projects
New signups
Quarterly pipeline activity
Weekly sales forecast
New collections this week
Scheduled reports are delivered by email that is set to send designated recipient at a certain period of the day.
Repetitive reports are better suited to be delivered automatically, rather than relying on the user to search for the data to act on it, the BI tool should deliver it automatically at certain periods of time based on when this data is required.
Scheduled reports are great for providing the right data at the right time for the right person.
2. Alerts
Alerts are reports or messages that are sent to a user or a department which are not time-dependent, instead, they are triggered (activated) on specific conditions that the analysts or user specifies. Alerts are great to pull your attention into a situation that requires immediate action or alerts you of a possible risk if the current path stays the same.
Some examples of alerts are:
Advertisement campaigns are under delivering
Over delivered campaigns (overspending)
Account deletions
Refund requests
Drivers (KPI) not reaching the intended target.
3. Goals and Scorecards
Goals are an advanced form of Alerts. Goals are present in a Performance BI tool.
Goals are set against any measure or metric required to reach an outcome in the business and are very useful in that they:
Provide feedback to individual user roles on what is essential to the business success at any given point in time.
Tells the team on which tasks they need to focus their effort on.
Provides them with the time span to gauge if they’ve reached the intended business goal before moving between tasks.
Managers or analysts can set goals for team members, without the need to communicate it in lengthy emails or meetings.
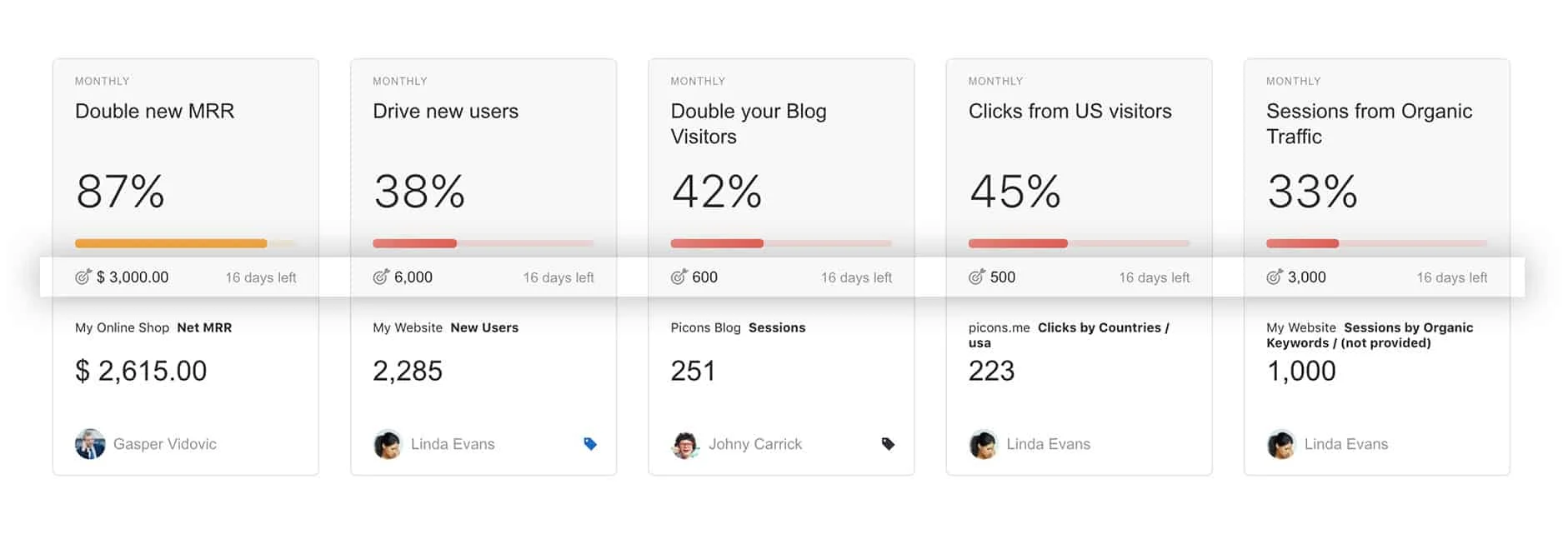
Scoreboards is another feature of a Performance BI tool. It allows you to select specific metrics that you deem important to you, from different sources, and have it delivered to you through push notifications and emails.
Scoreboards are a great way to get an overall health check at any point in time without the need to visit the BI tool and comb through the individual dashboards. You can specify a time and a day in which you’ll receive recurring notifications with those specific metrics,
4. Snapshots
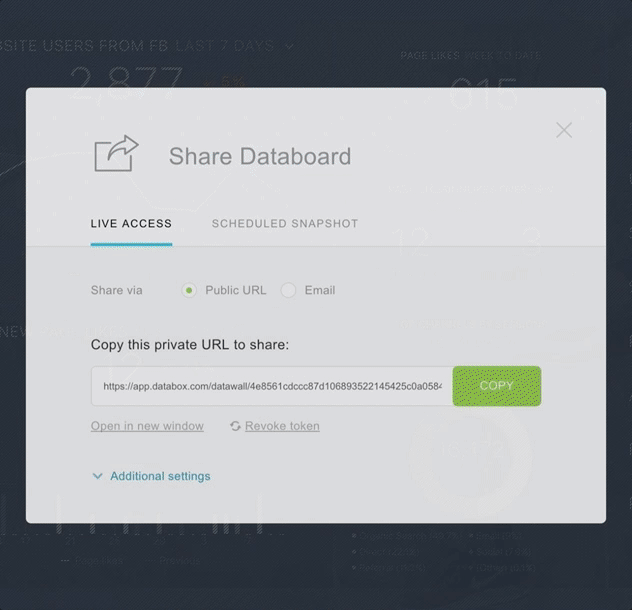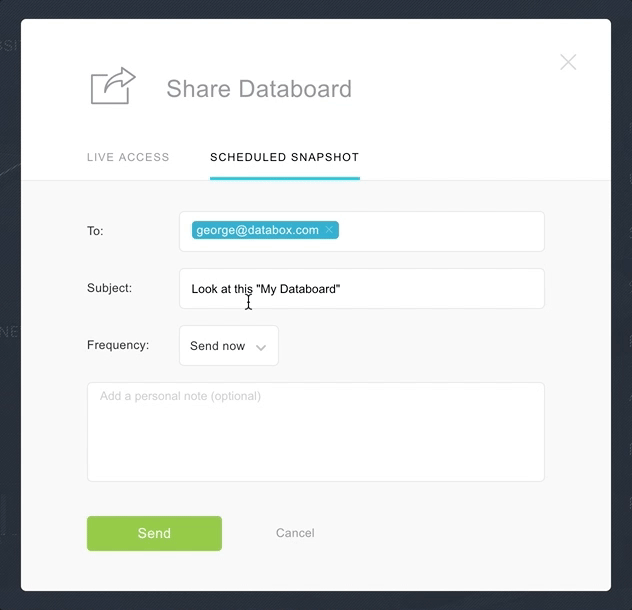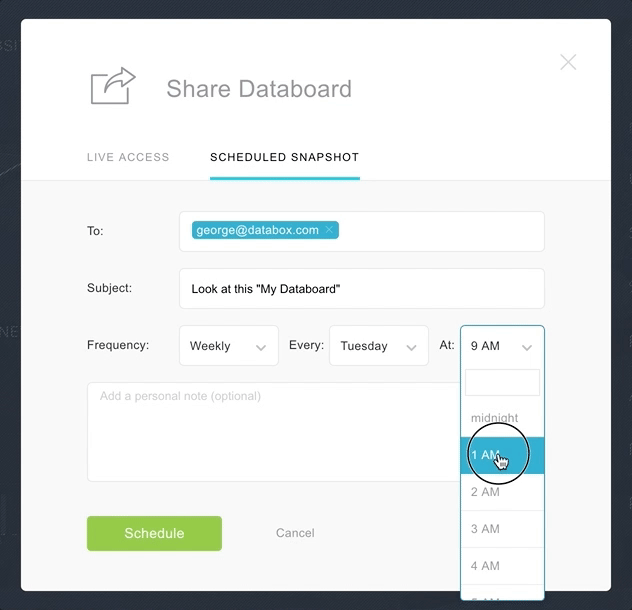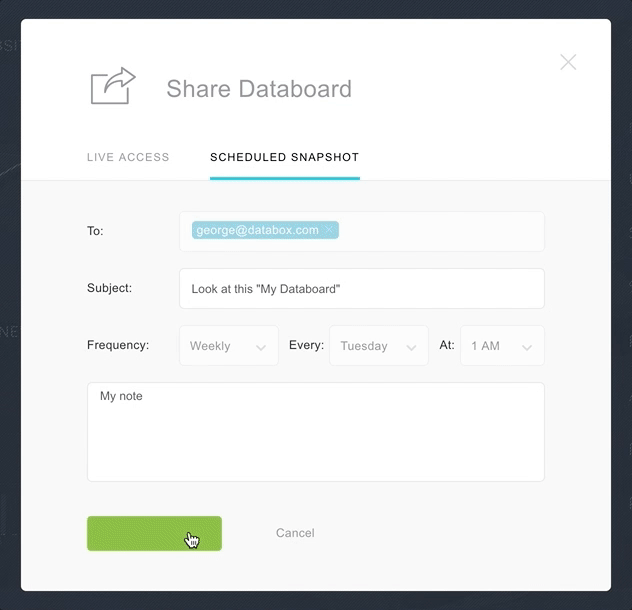
Snapshots take a screenshot of a specific dashboard and deliver it to a specific person or shared online. Snapshots are great for those on the move and require delivery of a dashboard automatically.
Snapshots are used to send formatted a performance report to a client, doing so removes the burden of giving them access to your company BI tool.
Any combination of the above tools can be found in a single BI tool. They are a huge time savour and increase productivity and usage of the BI tool in a company. The inclusion of those tools doesn’t affect the final pricing of the BI tool. However, they affect the usages of the BI tool in your company.
A BI tool provides all the tools necessary to help a business in data collection, sharing and reporting to ensure better decision making. Having said, most people would think a BI solution allows for business or data analytics. While related, BI and business analytics are not the same.
BI is the broadest category involving Data Analytics, Data Mining and Big Data. On its own BI refers to data-driven decision making with the help of aggregation, analysis and visualisation of data to strategise and manage business processes and policies. Traditionally, BI deals with analytics and reporting tools, which helps in determining trends using historical data.
Business Analytics, on the other hand, helps in determining future trends using data mining, predictive analytics, statistical analysis and others as well to drive innovation and success in business operations.
“Business Intelligence is required to operate the business while Business Analytics is required to transform the business.”
To understand the difference between BI and all disciplines of analytics we need to get familiar with the types of analytics we can perform on data. In the business question a BI tool can answer we explained that a BI tool provides answers to How, Why and What. we'll categorise these questions at a high level into three distinct types.
No one type of analytics is better than another, and in fact, they co-exist with and complement each other. For a business to have a holistic view of the market and how a company competes efficiently within that market requires a robust analytic environment
Those types are:
Descriptive Analytics, which use data aggregation and data mining to provide insight into the past and answer: “What has happened?”
Predictive Analytics, which use statistical models and forecasts techniques to understand the future and answer: “What could happen?”
Prescriptive Analytics, which use optimisation and simulation algorithms to advice on possible outcomes and answer: “What should we do?”
Business Intelligence is strictly descriptive, even more so, BI doesn’t cover all aspects of descriptive analytics. Because descriptive analytics is further broken down by the type of decisions required, those decisions are Exploratory, Descriptive and Causal.
Exploratory
Exploratory analytics is the first level of analytics done and usually done first. It gives you a broad understanding of what the underlying problem could be. The data collected for exploratory analysis can be from submissions forms, internet traffic, social comments, focus groups, internet communities.
Descriptive
Descriptive analytics tries to determine the frequency with which something occurs or the covariance between two variables. That data used for descriptive analytics are either passive (e.g. POS, social media, web data, audience engagement) or active (e.g. Survey’s, comments, reviews).
Causal
Casual analytics tries to find a causal link between two variables, cause-and-effect relationships. Casual analytics is not designed to come up with final answers or decisions.
One thing to add here, causal analytics is not about finding a correlation, as both are different.
Causation is one variable producing an effect on the other.
Correlation is the relationship between two variables.
A famous example of the difference is the Storks theory. There was a belief that storks caused fertility when scientists correlated the number of babies being born in houses with storks sitting on chimneys. The correlation was staggering. Conclusion: storks deliver babies!
A more reasonable way to explain that correlation is that people who care about their babies heat their home by putting an extra log in their fireplace. Storks like to build their nest on top chimneys because of the warmth it gives. So the presence of storks is caused by the heat, which is caused by families heating their houses for new babies in the winter.
Before we show what BI covers from the above analytics types, we’ll need to explore the other disciplines of analytic fields:
Business Intelligence (BI) is a comprehensive term encompassing data analytics and other reporting tools that help in decision making using historical data. BI vendors are developing cutting-edge technology tools and technologies to reduce complexities associated with BI and empower the business user.
Business analytics provides analysis as it relates to the overall function and day-to-day operations of a business. It’s process-oriented which involves analysing data and assessing requirements from a business perspective related to an organisation’s overall system.
The output of the business analytics task is an action plan that is under stable by company stakeholders.
Data mining is a systematic and sequential process of identifying and discovering hidden patterns and information in a large dataset, and It is also known as Knowledge Discovery in Databases, through the use of mathematical and computational algorithms, data mining helps to generate new information and unlock the various insights.
The output of the data mining task is a data pattern.
Data analytics is a superset of Data Mining that involves extracting, cleaning, transforming, modelling and visualisation of data with an intention to uncover meaningful and useful information that can help in deriving conclusion and take decisions. Data analytics is about exploring the facts from the data that results in having a specific answer to a specific question, i.e. there is a test hypothesis framework for data analytics.
A business needs various tools to the right data analytics and requires the knowledge of programming languages like Python or R to perform robust data analytics.
The output of data analysis is a verified hypothesis or insight on the data.
Data Science is one of the new fields combining big data, unstructured data and a combination of advanced mathematics and statistics. It is a new field that has emerged within the field of Data Management provides an understanding of the correlation between structured and unstructured data. Nowadays, data scientists are in high demand as they can transform unstructured data into actionable insights, helpful for businesses.
The type of roles that perform the different types of analytics is Business Analysts, Data Analysts or a Data Scientists. The graph below explains what type of analytics by the disciplines and the roles of analysts.
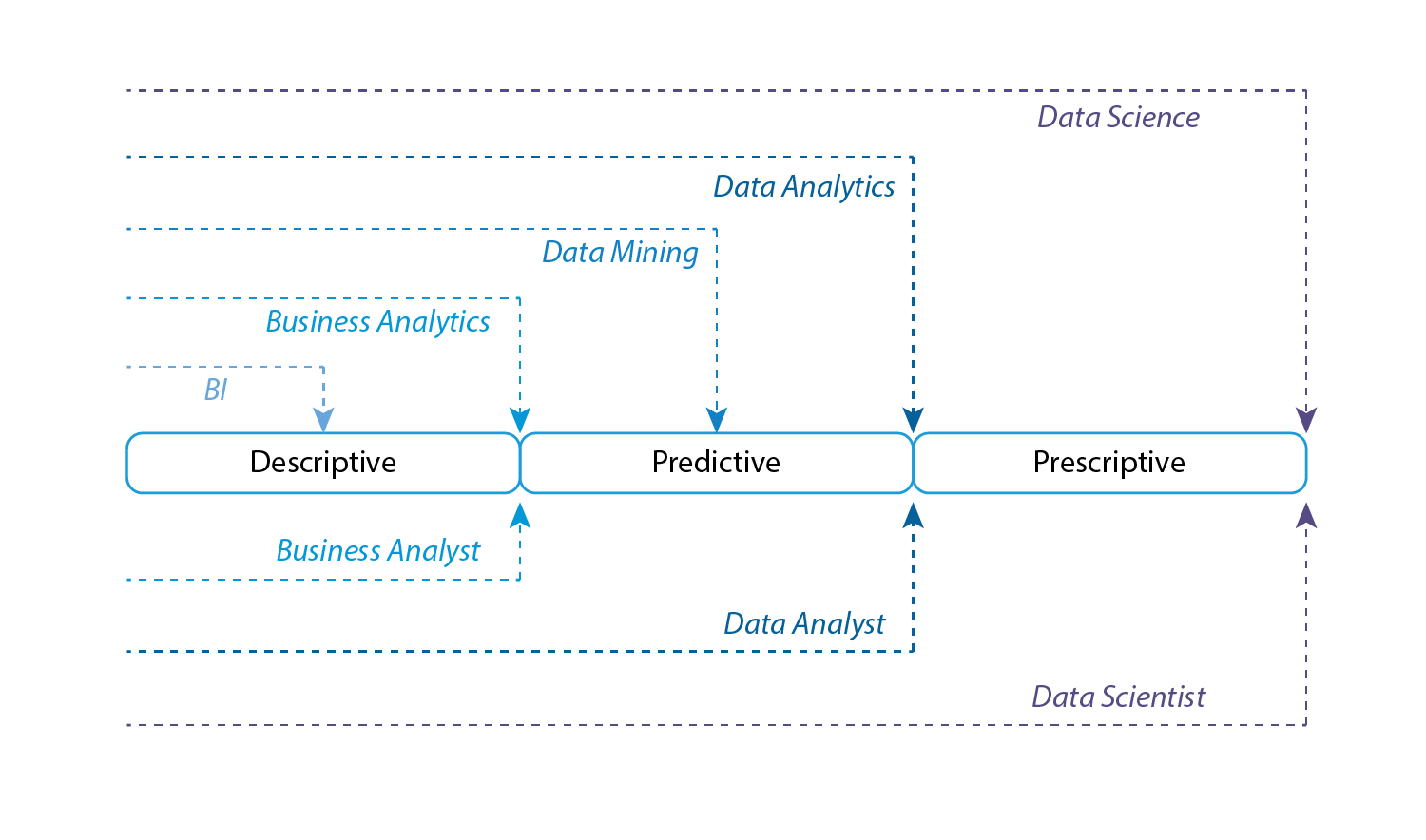
The most common field used alongside a BI tool is Data Analytics, and in most recent BI technologies both go hand in hand.
The significant difference between BI and Data Analytics is that Data Analytics has predictive capabilities whereas BI helps in informed decision-making that is primarily descriptive.
Data analytics, like vitamins, is good for a business, and if done correctly has the potential to increase traction and revenue drastically. Like vitamin though, it’s not a pill that you can pop in your mouth and your done, data analytics require continuous refinement.
BI and Analytics vendors are noticing the shift driven by big data and the need for businesses to combine historical with predictive and machine learning tools. Role of analytics is critical in extracting the relevant information and deriving actionable insight. Analytics is becoming a significant factor in decision making at any insights-driven business. Simple and easy to retrieve reports is a critical functionality required in data analytic tools. The current challenges faced by organisations is integrating the BI systems with the existing system and generate reports that offer actionable insights.
As such a BI tool that allows for smooth and seamless integration between the BI tool and any Data Analytics tool has a significant influence in the BI tool market position and pricing.
In July 2017, Gartner published its annual “hype cycle” graph that describes the status and maturity of all emerging technologies ranging from brain chips to self-driving cars. Notably, the report introduced a new concept called “Augmented Analytics”, which they claimed to be the “future of data analytics”, or simply put "Analytics for Humans"
In the report, Gartner describes Augmented Analytics as:
“an approach that automates insights using machine learning and natural-language generation, marks the next wave of disruption in the data and analytics market.”
To explain what Augmented Reality is, we'll need to understand the problem Augmented Reality is trying to solve.
In the Analytics section, we've explored the different types of analytics done on data, and what types of analytics BI solves, which covers most of the Descriptive Analytics scope. As such, makes BI suitable for Reporting and displaying data. You'll be surprised to learn that Analytics is not usually a function of a BI tool, Analytics has always been a separate process and requires particular languages and applications (e.g. SPSS, R or Python). However, in recent years there is with the explosion of data and an equal demand from companies to manage, explore and analyse data in a holistic view, BI vendors started introducing "some" simple analytics features in their BI tools. Examples of analytics features that layers on top of BI reports are:
Trends
Average lines
Median lines
Median with quartiles
Distribution bands
These analytic models are done for you and require minimal input from the user beyond drag and drop on the BI report, which makes it accessible for nontechnical users to get decent statics from the data in no time.
Bear in mind, that not all BI tools offer these analytics features. Correct analytics process is a different process from BI, so it's not easy for BI vendors to include a full-fledged Analytics process inside the BI application. BI and Analytics use different languages and different way of accessing and processing data (as we'll explore further in this guide). Also, in software development, it takes months of development and testing to release a couple of feature to an application, analytics is not a feature, it's a complete application on its own. So, to expect an established BI tool to become a 2-for-1 app is not practical. It's much easier for a new BI tool to be a 2-for-1 solution because the code of the app is young, and the vendors would have architected the application to accommodate both disciplines from the beginning.
However, analytics is much more than just those simple analytics. Today we require data mining, predictive modelling, machine learning, and AI. Those disciplines follow a complex process of data processing. They also require domain experience, knowledge of statistics and a degree in mathematics.
As an example, let's look at the steps required to perform a simple regression analysis between two data variable, we'll demonstrate the steps used for a Linear Regression. In statistical modelling, regression analysis is a set of statistical processes for estimating the relationships among variables.
Select the sample size. Are you running tests on 10,000 records or 10,000,000 records? Does this sample size represent all of your data variables?
Clean, label and format the data, this probably take most of the analysts times.
Select the set of variables you want to test for a relationship (i.e. the dependent variable and independent variables). For example, if you want to increase the close deals rate, then the close rate would be the primary variable. The rest of the variable are chosen either automatically or manually.
Automatic means the Analytics app goes through every column in every data source and run a regression analysis against account close rate.
Manual means the analyst needs to choose the variables to test, were the right variables picked? (this is where domain expertise comes into play, the better the analyst knows about your business domain the more helpful the analysis is)
Create new variables if the current variables are not enough.
Check the distributions of the variables you intend to use, as well as bivariate relationships among all variables that might go into the model. If the distribution is not satisfactory, go back from the beginning, rinse, repeat.
Run the variable through regression models, you'll need to find the model that satisfies the research your conducting. There are several models to test with:
Linear Regression
Logistic Regression
Polynomial Regression
Stepwise Regression
Ridge Regression
Lasso Regression
ElasticNet Regression
Refine predictors and check model fit. If you are doing a genuinely exploratory analysis, or if the point of the model is a real prediction, you can use some stepwise approach to determine the best predictors. If the analysis is to test hypotheses or answer theoretical research questions, this part will be more about refinement.
Test assumptions, if the right family of models were investigated, variables thoroughly investigated, and the right model was specified, then this step will be about confirming, checking, and refining.
Interpret the final results, communicate those insights with the organisation and convert them into action plans
The above steps goes for every predictive analysis. AI and Machine learning are even more complicated. So as you can see, this type of analysis is best suited to be done by data scientists or data analysts, both of which are scarce and expensive to hire, making it extremely cost-prohibitive for smaller businesses to leverage analytics.
Even with the right person, it takes some time between the business request is made and getting the results and action plans. Data analysts or scientists spend over 80% of their time doing data preparations tasks, from labelling to cleaning the original data sources, as well as doing regression analysis, which is a waste of the analysts time and the investment of the business.(read more here). Therefore, a typical data scientist only analyses a small portion (in some instances an average of 10%) of your data that they think has the most potential of bringing you great insights. Meaning you may miss out on valuable insights in the remaining 90%, Insights that may be mission-critical for your business.
For these reasons, almost all SMBs are still in the early stages of analytics adoption, despite a strong desire to leverage their data.
Those challenges faced by businesses are not going away anytime soon. There won't be a sudden spike of data scientists to solve the talent shortage anytime soon. Neither can you expect that data analysis becomes easier to do for non-technical business people?
That’s where augmented analytics comes in. What augmented analytics does is to relieve a company’s dependence on data scientists by automating insight generation in a company through the use of advanced machine learning and artificial intelligence algorithms.
“The promise is an augmented analytics engine can automatically go through a company’s data, clean it, analyse it, and convert these insights into action steps for the executives or marketers with little to no supervision from a technical person. Augmented analytics, therefore, can make analytics accessible to all SMB owners.”
Augmented Analytics is at its infamy, still an emerging technology. As such, each BI tool having their interpretation and implementation of this technology. Software development and architecture is a lot like building a house. If the house plans are still in the blueprint stage or the foundation's stage, it's easier to make any changes to the house. However, a finished house which requires expansion of the toilet floor space, it's a simple job, as long as foundations stay in place, and the basin stays in place. Ohh you want to move the basin, God helps you.
As such, established BI tools attempts of Augmented reality are nothing short of a patch job, which is done mostly by allowing Analytics tools access to the BI data sources and having the analsys displayed in dashboard alongside other BI reports. In our house analogy, this is a lot like building a garden shed. Other emerging tools are taking a better-integrated approach, Microsoft Power BI integrates Augmented Analytics in two way:
Finding quick insights about your data set, this is nothing more than running correlation analysis on all of your data, most of the results are mediocre (e.g. there is a strong correlation between the day Tuesday and the close rate for deals, so clap your hand twice, stomp your foot and send the proposal on Tuesday)
Finding the drivers for a given result in a report, which opens a report that shows all the drivers for that particular result and segmented into several categories. Why functions are more useful than quick insights as it relates directly to the data.
The best implementation we've seen to date for Augmented Analytics is courtesy of Salesforce Einstein Discovery (Salesforce Einstein solution is discussed in greater depth later in this guide)
Salesforce Einstein Discovery is part of Salesforce Analytics solution, and it’s tightly integrated with Salesforce CRM. Which means you’ll need to use Salesforce CRM for Discovery to work.
If we were to tackle the same steps required to increase the close rate example, these are the steps required inside of Salesforce Einstein Discovery.
Select the Close Rate as the metric you want to increase.
Pick the data columns for discovery to analyse (Discovery have a powerful Natural Language Processing (NLP) engine so that it can analyse written notes as well)
Discovery takes 75% of this data and runs regression analysis on them
Discovery uses the remaining 25% to test the predictive models against the 75% data
Start the analysis
Resulting data graphs along with actions plans are given to the user.
This processes usually takes anywhere from 5-10 minutes.
Up to this point, Discovery presents the results like any other BI and Analytics integration (albeit with more intelligence and with an action plan), providing analysis on a separate report. Discovery takes a fraction of the time than other solution, and yes the analysis is performed by any users, but what makes Discovery stand out from other implementation is what happens after that last step, which puts insight into context.
Besides the stand-alone report, all the action plans to increase the close deal rate sits in the sales rep deals page. Discovery embeds itself in the side and provides the sales rep with a probability of closing this deal and what are the recommended steps to increase that probability to win the account (taking into account the sales rep data, customer data, similar industry trends…etc). Each time the sales rep executes on the recommended list the probability increases.
You can combine multiple insights into the same report. There isn't any limitation to the number of insights (to increase or decrease a metric) you want to create, so, for instance, you might want to get insight on how to close a deal faster as well. Same steps as above, and now the sales rep have two insights that help in winning the deal and closing it faster.
A nontechnical person performs this analysis in the manner of minutes. Not only does Discovery provide unparalleled ease of access and use to predictive modelling, but it also cuts down costs significantly to the business as the need for an in-house analyst are not required.
In this chapter, we’ll take a look at some real-world examples of BI implementation in small and medium businesses. We’ll bring examples from two business. A small company in the health and fitness space, the challenges they faced operating in the digital space, and how BI helped them. The other example is from a more established business, how BI was implemented to solve a business process to allow for growth without the need to hire extra team members.
The examples provide a complete background story along with the business challenges, the logic of the solution and the outcome. Providing this level of information helps you in understanding the context on why and how the solution helped the business.
- Ch3.1 Performance Marketing
- Ch3.2 Process Optimisations
Background:
This first use case explores a health and fitness company selling on-premise accredited courses and online training models. The company have been operating for 9 years in Sydney. The core business team is small, and most have been with the business from the start, the company had various contractors throughout the year as well. In the beginning, most of the marketing and sales were through events, council promotions, exhibitions and health and fitness publication. The company have transitioned to digital marketing almost entirely 4 years back.
The business revenue was a little shy of $400,000 in the last financial year. The Marketing cost for the same year was $90,000, while the remaining revenue spent on fixed costs and wages, with no room for profit.
Challenges:
The company was facing several challenges that kept on growing year after year, mostly because of the shift in the digital landscape and the team couldn’t cope with the massive changes. The main challenges were the following:
Burdon of technology. The company have been picking up tools to operate the business as needed. Those tools were spiralling out of control, which meant if a team member or a contractor introduced a tool, no other member of the team could pick up the tasks if that person were not present. It also meant most tools needed an outsource contractors to maintain and updates.
Tools fragmentation. With as many used tools, fragmentation is always present. Records stored on multiple spreadsheets and system (locally, DropBox or Google Drive). Multiple payment gateways, multiple booking systems, various marketing and sales tools or sheets. There was little or no integration between any of the tools. This type of fragmentation is of a massive cost to any business.
Client support and servicing. Fragmentation first casualty is usually client support. It takes longer to edit or find records, simple tasks that require minutes ends up taking an hour or more. Data duplication is error-prone and usually not updated (customer activities need to be collected by hand from one tool to another). The result of all of it is an overwhelmed team member that keeps on dropping the ball with their customers.
Visibility. The business had no visibility on how the business was operating beyond the financial spreadsheets from the bank feeds and accounting solution. There is nothing to measure, or improved upon because of the lack of data. Even if all the tools they’ve been using did provide them with a wealth of data, they didn’t know how to use them. For instance, they couldn’t tell a customer who purchased a course was a result of a marketing campaign they performed or the originating channel.
Growth. The company didn't have any growth. Their year on year revenue was shrinking by 30% on average, year over year.
Solution:
Business Intelligence was pitched as part of a five months Digital Transformation project with an investment of $50,000. The project addressed three main areas for the business:
Systemisation:
Consolidating all the business tools into one core business tool (CRM implementation that included sales records, customer records, custom objects for events and training, booking, online payment gateway, campaigns and automated marketing).
Guided systemised business processes, which allowed any team member to pick a task with clear outcomes and follow up tasks.
Unifying the company websites, migrating to a modular growth-based design that can be updated and built by the existing team members.
Automation:
Integrating all cloud-based tools which feed information to a central CRM system. Automation relieves human data migration between application, usually done by a human and results in data entry errors.
Automating client inquiries, follow up emails, collection email, customer onboarding emails.
Reports and records automation for events and courses.
Analytics:
Setting baseline measure for all the business activities and KPIs. If you cannot measure it, then you cannot improve it.
Providing a complete tracking workflow for customer journeys (Marketing and Sales).
Business Intelligence to provide the business with a complete insight on the business operation and future decision making.
BI is an integral part of growth and the success of the project. As such, we’ve asked the marketing, sales and delivery team member to take a behavioural profiling audit.
Most larger organisation are familiar with behavioural profiling practices and actively exercise them for recruits, for smaller businesses though, this might seem like an odd step to make. The truth is, there is an application for every problem, however, if no one in the business is going to use this application or solution, then nothing changes for the company’s bottom line. Tools don’t operate on their own. They need a user to operate and make the most out of them. When a medium or a large company introduces change, there is little or no resistant amongst the employees, because the business at that point have processes already in place, and every team member knows their tasks and how to perform them with ease. If there is a resistance to change it usually sits with upper management and senior executives.
Smaller companies and start-ups are different in that the team members are usually multi-disciplinary, they perform more than one task (one person does marketing: blogging, copywriting, EDMs, paid marketing, social marketing), and they are closer to the business founders. In a nutshell, they operate as a family. If there is a resistant to change, then the effect on the business is enormous.
Behavioural profiling gives us three critical insights in implementing a solution:
How the team operates
Who’s going to resist changes
How to introduce the changes
Analytics and BI is a left-brain process, it’s logical, analytical and objective. Right-brain, on the other hand, is emotional, imaginative and subjective. All of the team members were an S and an I, which meant they are kinesthetic, emotional, creative, visual learners, they seek togetherness, community and most importantly they don’t want to be bound by numbers to operate. BI is the complete opposite of all of those things. Our early tests proved a high resistance to change and in some cases refusal of the solution altogether.
Outcome:
A three months tracking and analytics audit proved that all sales were not directly generated by marketing. Paid advertising (40% of the marketing budget) did not generate any customers. EDM (60% of the marketing) had little influence on the buying decision. 90% of customers were new leads generated from organic search results. All paid media advertising was suspended and directed to nurture organic leads and website visitors, based on visitor data.
BI gave management real-time insight on how the business operates and the decision needed. By breaking down the results into their drivers, they were able to communicate the required goal and benchmarks to the team. The directors of the business were able to keep track of goal completions. The team still doesn’t access the BI solution but are happy to receive simple guided goals and measure for each of their tasks.
The business reached their previous year revenue in the first three months of the project. The remaining two months of the project the company went over by 60%.
Background:
The second use case explores a Media Agency that manages performance campaign for brands. The agency is a start-up with a $13,000,000 yearly revenue. Their growth was 20% year on year. However, as many start-ups with a growth phase there was no profit. The agency had offices in several cities and a relatively average team of 40, which included sales, production, IT, media buying, business analysts, finance and management.
The agency wanted a BI solution that would help in process optimisations to reduce operational costs, generating new products and increasing profit margins.
Challenges:
One of the main challenges of the business was on the reporting side of things. The business wanted a streamlined version to prepare reports for their clients. Their early attempts included building a bespoke booking system which wasn’t successful in fixing the problem.
Sales would acquire an account to run a digital paid campaigns for a brand. The campaign then gets passed to the media buying team that have three main areas of responsibilities:
Setting up the campaign on all partner channels and traffic the campaign line items.
Monitor and optimise the campaign performance based on the campaign metrics.
Report on the campaign performance to the sales team, the client and the finance team.
The media buying team consisted of 7 team member, and the agency was actively recruiting more positions for this role. On average the agency was trafficking 150 campaigns per month. An example of a campaign is Coca-Cola Summer Fun. A campaign has 7-8 targeting criteria on average. An example of targeting criteria is male between the ages of 18-24 living in metropolitan Sydney. Each targeting criteria is made up of an average of 6 different creatives. An example of creatives is Video, Interstitial, banner or an mrec. So a media buying team member needs to set up 48 creatives on average for each campaign, monitor and optimise each one daily. More so, a single campaign runs across 3 different channels on average. Meaning a single setup is 144 creatives. The agency had 44 different channels.
When it comes to reporting, a media buying team member needs to visit every channel, download individual reports for each creative, target and campaign. Combine them in a spreadsheet. Format and clean. Then send to the client, salesperson or finance team. The media buying team spent 80%-90% of their time on reporting. With little to no room for optimising. Also, requests made by the sales team to check campaign performance were not met on time or completely ignored because of the workload. Also, the biggest department that was suffering (besides the media buying team who usually worked 12 hours per day) because of this manual process where the finance team. The agency sends their end of month invoices at the beginning of every month. To generate those invoices five things needs to happen:
Collect all trafficked creatives and lines items from all channels for a campaign in this month. Since the finance team doesn’t know anything about advertising and media channels, the media buying team would need to generate those final reports, which is always late.
Name each campaign and targets with the insertion order name and campaign prefixes.
Check each delivered target metrics against the insertion order. Since insertion orders cover the whole span of the campaign and not a single month, the finance team needs to split the period manually and determine the required delivery for each month, compare it to the delivered for that month, check older invoices and the remaining before generating each line,
Compile a report and send to each sales person to double their the delivery and IO numbers.
Generate an invoice for each campaign which breaks the targets as items in the invoice.
The processes to generate an end of month billing for a given month was a 2 months process.
Solution:
BI is a perfect solution for such processes. Collecting internal operating data and external operating data and report on them is at the heart of what a BI tool offers. The BI solution took 8 months to implement, which involved massive back-end development and implementation for all the different data sources, as well as the modelling of the data and reports generations.
The resulting BI was collecting data from the business CRM, booking system, 44 advertising channels, and accounting software. Drillthrough dashboards created for every department and even individual roles in the business. Data was refreshed daily and reported on a daily basis.
Outcome:
Reporting is done automatically and freed up 80% of the media buying team. In fact reporting happens by one of the following ways:
A client can subscribe to a specific report that is delivered to them daily, weekly or monthly. Formatted and cleaned.
A media buying team can subscribe a client to a specific report.
Creation of scheduled reports involves a few steps. Delivered to a client destination or a BI tool.
Media buying team can generate a new report to match client needs with a few simple steps.
Sales have access to all campaign reports and can pull all relevant data with a few clicks.
Finance team have access to accurate, segmented, calculated, formatted, checked and paced reports at any given time.
Today, the end of month billing processes takes one day, as opposed to the 2 months old process.

Ch4. BI Components
The Back-End OF a BI Solution
There is a great deal of effort that goes in implementing a BI solution for any business. Most of that effort doesn't sit with the BI tool itself. Instead, it relates to the back-end requirements for the implementation. This effort is in contrast to what BI tools publicise of a plug and play solution. In a perfect world, a plug-and-play solution is possible, for the real world though, BI implementation goes through several back-end stages before generating any reports or insights. Depending on the tools used in the business and the insight requirements, these back-end stages can take anywhere from a few weeks to 6 months or more. Aside from the additional time, back-end stages have the potential to add tens of thousands of dollars to the implementation budget.
This chapter explores all the back-end implementation stages required for a successful and useful BI solution for a business.
- Ch4.1 Data Sources
- Ch4.2 ETL
- Ch4.4 Connectors
- Ch4.3 Data Warehouse
- Ch4.5 Data Preparation
Defining Data sources is a planning step which happens early in the implementation phase. This step focuses on identifying 2 areas:
Listing all data sources and defining hierarchies and relationships between them
Identifying how data exporting options from each data source
1. Listing and Identifying Keys
The first objective of this planning phase is to to make a list of all of the data sources you want to pull information from, group them between Internal and External data sources. Most often than not those data sources are discreet with no connection or relationship between them.

Relationships and references between data sources is an essential step of a successful BI implementation. Having arbitrary and discreet data sources without any relationship results in broken reports. The way to perform relationship between data is through identifying the Primary Keys and Foreign Keys in each of the data sources used in the BI tool.
The primary key consists of one or more columns whose data contained within are used to identify each row in the table uniquely. You can think of the primary key as an address. If the rows in a table were mailboxes, then the primary key would be the listing of street addresses. When a primary key is composed of multiple columns, the data from each column is used to determine whether a row is unique.
A foreign key is a set of one or more columns in a table that refers to the primary key in another table. There aren’t any unique code, configurations, or table definitions you need to place to officially “designate” a foreign key.
As an example, assume you have the following sources of data in your business:

CRM system that manages all the business and sales operations. You have company users, contacts, organisations, and opportunities.
An accounting software which includes records for companies and suppliers with all transactional data.
A project management software with company users and projects
If one of the questions a BI tool should provide an answer to is: How much was invoiced to contact X in the last 6 months?
The first issue we have is that the accounting system doesn’t include any contact information, it only stores company details. On the other hand, the CRM have both contacts and companies. So how can we relate contacts to invoices?
To do so, we would need to identify companies in both applications and match them together through a unique identifier, in this case email (a company email) is the identifier.
Using a company name as an identifier is a bad idea since text can be different between systems and it’s not reliable.

Internally the CRM system would have created a relationship between the contact and a company by pointing a company to the unique ID of each contact in the system. In this case, ID is a primary key, and the companies record includes a reference to all those IDs through the hidden contact_id. This relationship is already in place and is provided to you by the CRM, so when you export the data from the CRM for the contacts and companies, those fields are present in each table.
For the accounting system though there isn’t a direct integration between both platforms, meaning we’ll have to plan which fields are the primary or the foreign keys. The email field in the CRM system can be considered the primary key, since it’s unique for each company, while the email field in the accounting system is treated as the foreign key later in the modelling phase.
The actual process a BI processes this query might be something like:
Find the contact details by name and select the contact ID
Select the company by contact_id AND select the company email address
Select company details from accounting application by company email address
Select the invoice amount for the company filtered by the duration requested
Display result of contact with invoice amount.
This process highlights the first issue and the primary purpose of listing and identifying keys between the data sources, we need to make sure the fields we designate as keys need to match between systems. If the CRM company email field is info@acme.com while the accounting system has the email field set to finance@acme.com, then when trying to perform any matching in the BI tool won't return any result.
Another example would be to generate a tabular report that lists all projects currently active, alongside their respective companies. Looking back at our diagram we’ll notice that the Project Management application doesn’t include any information about a company, the name of the company might be referenced in the project name somehow, but that’s not enough to make sure that a relationship can be made based on the name alone
As explained previously, text strings are not suitable for identifications, that’s because the text is user-generated. User-generated fields exhibit many issues, from typo errors to naming mismatches. The addition of a single space in the name might break the matching between names, lowercase and uppercase letters break the match. This type of mismatch often occurs between applications, especially in the absence of a strict naming convention policy for field naming.
In the case of a mismatch in our example, several solutions can be implemented to solve this issue.
One solution would be to create programming scripts that perform string manipulation on text strings upon exporting, however, this is time-consuming to implement in most cases.
A better option is to create custom fields in the PM application that allows for the manual input of foreign keys in the application (e.g. adding a company name field and a company email field in the project information records). This approach is the most common, the implications though is a fair amount of labour work to perform to update all previous projects manually.
Another solution would be in automating the creation of a project from the CRM application into the PM application through the use of API scripts or API helpers. This approach ensures that data from the CRM is used to populate the fields in the PM application without the human intervention (which is prone to errors). How easy is it to implement this solution depends on the availability of API integration options between the data sources currently used as well as the technical resources available in the company.
In all cases, having a strict naming convention policy in a company for field names would make this process much more manageable in the long run.
2. Data Exporting
The second objective of this phase is to understand how each data source exports the data. Here are the main questions we’re trying to answer:
Can we extract the data through a spreadsheet?
Is there an API to extract the data from each data source?
Which applications provide API connectivity and which applications provide a spreadsheet export?
How often do we need to extract data?
Is the extraction done manually or automatically?
Can we schedule exports?
How frequent?
What tables can each application export?
Having a clear answer to all of the above questions in advance indicates how involved will the next step of the implementation be, and how much-required resources (internal or external) needed to export the data, which in turn impacts the BI solution implementation cost.
The data sources planning phase is generally overlooked by some companies, as most BI implementation begins by picking a BI tool first and figure out the rest of requirements from there. This approach is costly and not recommended as it inflates implementation and running costs considerably. Planning and identifying issues early in the processes ensure a smooth implementation and tighter control of the budget and time to implement.
For some companies, the planning phase helps in identifying significant shortcomings in their current applications currently used. It is not uncommon for a company to decide on switching the core business applications at this stage in favour of better integration with the BI solution. This step might even prove to be the most cost-effective than trying to solve the shortcomings by going through a development project. In either case, it's better to map all of the issues beforehand to mitigate budget and time inflation risk.
The ETL stage is an implementation phase that deals with writing scripts that perform extraction of data records from all sources, identified from the Data Sources stage, and perform various transformative manipulation on the underlying data and loads the result on a Data Warehouse. From there the Data Warehouse will either allow further manipulation on the data through the Data Preparation stage or load them directly onto the BI Tool to start the modelling and reports generation process.

ETL is performed and implemented entirely by an IT department, either in-house or through an outsource agency. ETL stage takes a considerable amount of time to implement and can add a significant additional cost to the BI solution budget, as the choices made at this ETL stage have a significant impact on the final pricing of the BI tool you choose.
So what is an ETL layer?
Extract
An Extract is a process of reading (extracting) data from one or multiple data sources (Desktop Application, SaaS, a Hardware or an IoT device, an Online Service or a Web Application). This extraction happens either through an API connection (i.e. programmatically) or by importing a spreadsheet (manual import or online retrieval). Programmers perform the extraction by writing scripts for each data source.
Data extraction from data sources happens in one of the following three ways:
Spreadsheets. Either by exporting a manual report or scheduling a report to be generated. A spreadsheet is an option for a data source that:
doesn't offer an API or direct database access,
is not used periodically, as such doesn't need a full-fledged ETL integration,
Needs only a small portion of data exported as needed.
Database connectivity, having direct access to the underlying data source database system. This type of extraction is rare amongst companies unless you are:
A SaaS company and have access to the database of your SaaS product
Having built a bespoke application that runs on your servers.
A large company which run an on-premise license for all of their company applications.
API access. Using a programming interface to access some parts of an application database. API is the most common method of connectivity today, and it's probably the only method for most SMBs.
So why don't all software applications provide direct database access to their customers?
With a cloud application, a customer shares the application resources along with other customers (i.e. Server, database, bandwidth). When you think of servers don't think of Amazon AWS IaaS or Microsoft Azure IaaS solutions, these are still shared resources, and are considered cheap in comparison to having your physical servers. Running a server is more than just a computer with CPU, Memory and a Server OS, there is internet connectivity (not your typical ADSL or NBN) costs, cooling and warehousing, routers, administrators, backup generators, software licenses and security policies. Moreover, because a single computer can serve a specific number of users and simultaneous processes (depending on the computer and internet specs) the complexity and cost are increased when scaling your servers to two servers or more. So resource sharing, multitenancy or virtual private servers are a much cheaper option, and it's the reason why cloud applications are more accessible these days. However, with cloud applications, the risk of giving you access to the database means getting access to all of the database, which potentially means you get to access every other customer's data. Even with security policies and access restrictions, you still have access tot he database, which is the bank for any application. The risk to circumvent those security and restriction policies are high, and as such, no customer is allowed access to the database in a cloud application. Instead, cloud application provides API access points instead. APIs are specific programming routines that returns controlled results.
Transform
Transform is the process of converting the extracted data from its raw format into the designed format to successfully load into a database or a data warehouse. Transformation also happens on tables that require constant manipulation and are known not to change between different extract cycles.
There are three types of transformations applied to extracted data:
1. Standard Field Transformation:
When exporting records from data sources, the resulting data might need cleaning or conforming to a naming convention. Typical tasks in the for a standard field transformation may involve the following:
cleaning (e.g., mapping NULL to 0 or "Male" to "M" and "Female" to "F"),
filtering (e.g., selecting only specific columns to load),
splitting a column into multiple columns and vice versa,
joining together data from multiple sources (e.g., lookup, merge),
transposing rows and columns,
applying any simple or complex data validation (e.g., if the first 3 columns in a row are empty then reject the row from processing).
Let's give a couple of examples of data that needs transformation:
If we exported data from a CRM and an accounting system, the CRM application might name a company name field “company name” while the Accounting application names them “organisation”.
Date and time fields might be represented differently between application. The Accounting data might represent "Date" in a UNIX time (UNIX Epoch time) format instead of a Gregorian Calendar (Human Readable Time) time format. (e.g. 1537444800 converts to 20/09/2018 12:00:00 (UTC)). Some BI don't convert time from a UNIX Epoch time. The resulting field will is considered a number.
Time-zone transformation, where a date and time fields need to convert from a UTC timezone to your local timezone.
These types of transformations are standard because the application always outputs data in a format that require those transformations, so the transformation is executed systematically on every data extraction cycle. This type of transformation is better handled by code early in the processes, as opposed to relying on the Analysts to perform those transformations in the Data Preparation stage or the BI tool, this is because most BI tools don’t have the means to perform any transformations on data once loaded into the BI tool.
2. Complex Transformations:
Sometimes you want to perform transformations on exported data that is more involved than joining tables or changing column names or types. One example of this is portioning. Let’s say your business sells online courses. One course sells for $10,000 and delivers for 4 months. Your CRM system probably lists the course as sold with a value of $10,000, however, that $10,000 pays through a 4 months plan. So if you sold one course this month, did you make $10,000 or $2,500? What if the student quits in the second month?
In this situation, we’ll generate a script that takes the total value of the course, and divide the payments according to the start date and end date in each month. So when the data gets exported from the CRM, it has the course name and value along with the start date and end date. The transformation script splits that row into 4 new rows, each representing the amounts to pay for each month. The resulting rows generate a new table that represents the actual division and gives a better representation of revenue.
This type of transformation is common for many businesses and used widely with digital agencies that provide performance advertising, where revenue ties to many leads they are to provide on a daily basis.
Doing those types of calculations or transformations in the ETL stage goes back to the limitation of specific BI tools, this type of calculation requires the richness of a programming language, which certain BI tools don’t offer besides SQL type of operations.
3. Data Modeling:
Data modelling is the process of connecting multiple tables in a database, or multiple databases, to one another through a relationship. It is a core practice of an ETL stage which ultimately determines the type of insights you can generate from any BI tool.
To understand the importance of data modelling and the role it plays in data analytics we'll need to understand how application and BI tools write and read data from a database.
All applications, cloud-based or desktop applications store data in a Database. A database is an application, just like a spreadsheet application but more sophisticated, that allows you an application to store data in tables, columns and rows. There are two types of databases
SQL Databases
NoSQL Databases
SQL databases are structured databases, which means the tables, columns and rows are predefined through a schema. For example, an address book table has a first name, last name, email, phone number. Each field is a column. Each has a specific type and length associated with it that defines that type of data stored. So one cannot enter a name in a phone number field. Also, this means unless the table already defined a second phone number, you cannot add one. SQL databases use a Structured Query Language (SQL) to access the stored data. If an application uses an SQL database then regardless of the programming language used to develop the application, when reading, writing, updating or deleting anything from the database, those commands are executed using SQL.
NoSQL databases are the complete opposite of a structured database, has a dynamic schema for unstructured data, and stores data in many ways: it can be column-oriented, document-oriented, graph-based or organised as a KeyValue store. This flexibility means that:
You can create documents without having first to define their structure
Each document can have its unique structure
The syntax can vary from database to database, and
You can add fields as you go.
SQL databases are widely used in application development and for obvious reasons they are are the only type of database supported by all BI tools. BI doesn't play well with randomness. It requires a structure to define relationships. Since the structured database is the supported storage for BI, we'll focus on structured databases and how they pertain to a BI tools design.
In the previous section Data Sources, we've touched on the concept of Primary and Foreign keys. This simple concept is the at the core of how relationships happen between tables. In fact from these primary and foreign keys we can create the following relationships:
One to one: A student has one student ID, a student ID belongs to one student.
One to many: A company have many employees, and many employees belong to a single company
Many to many: A salesperson has many clients, a client belongs to many salespersons in a company.
When developing an application, most of the development time goes on designing those tables and their relationships, called models. The rest of the development goes into designing the interface and defining how the models access the data. So a final diagram of a structured application and the relationships between the models could look like the following store structure:
Relational databases are stable, flexible and work well for online transaction processing (OLTP) databases. The design of it follows Inmon Entity Relational Modeling (ER Modeling). A transactional database, or OLTP, doesn’t lend itself to analytics very well. Due to the relatively high volume of tables, sophisticated computer programs are needed to navigate the tables to obtain meaningful information. Also, the need to "join" multiple tables can also create performance issues.
Before we move on to explain how OLTP affects performance, we need to define a few concepts first:
Transactions: A transaction, in the context of a database, is a logical unit that executes data retrieval or updates independently. In relational databases, database transactions must be atomic, consistent, isolated and durable, summarised as the ACID acronym. A transaction defines as a group of tasks. A single task is the minimum processing unit which cannot be divided further. In other words, a transaction is a unit of work that you want to treat as "a whole." It has to either happen in full or not at all.
A classic example is transferring money from one bank account to another. To do that you have first to
open the account,
retrieve the old balance,
withdraw the amount,
assign the new balance,
deposit the money into the destination account.
The operation has to succeed in full. If the operation stops halfway, the system loses the money.
Hierarchy breaks down dimensions into navigational paths which you can use to get to a more granular level of detail in the data. An example of this is a report giving you a view at a sales performance by region, you want to drill down to a specific country of that region, and you might also want to drill-in further into a country to view performance by a city.
Grain: The grain of a data source defines precisely what a data record in the source represents. It specifies the level of detail captured in a source. In other terms, how granular or detailed do you want your data to be, or how deep your data goes. In the example, those sales measures are they captured by a customer or even deeper down which is by the transaction? If the individual transaction level is agreed to be the lowest depth of the data, then transactions are considered the grain.
Another example would be looking at your online conversions levels. Are you viewing those conversions per day, hour or minute? If the agreed grain was hourly then all data sources (e.g. ads from Facebook, Google AdWords and Twitter) must all contain conversion measures on an hourly basis. If one source fails to provide the same grain of data, then that grain is not suitable.
The deeper down you go down with your data, the more data you have to both account for in your project and to calculate for the end user. So commonly the grain must be agreed on before picking dimensions and measures.
Table Joins: When you import multiple tables, chances are you’re going to do some analysis using data from all those tables. Relationships between those tables are necessary to accurately calculate results and display the correct information in your reports. Data joins the process you undertake to connect those relationships between two or more tables. The most common joins are:
As you’re building those joins between tables in steps by generating new joint tables, you’ll end up with specific tables that can be used to generate the Fact Table.
Fact Table consists of the measurements, metrics or facts of a business process. It sits at the centre of a star schema or a snowflake schema surrounded by dimension tables.
Now that we have an understanding of the necessary data modelling concepts let's explain why OLTP is not suitable for processing this with an example. Let’s assume you’re pulling data from Facebook Advertising platform. At a minimum level, you want to be able to display reports of the different ad creatives and various performance metrics (i.e. impressions, link clicks, post likes, link shares, and conversions). When importing tables from Facebook API, you realise that this data comes from different entities (or tables) and the tables group in a hierarchy.
The top level you have a campaign, which includes several dimensions (i.e. the name of the campaign, the budget, the start and end date …etc) as well as the aggregated measures (i.e. impressions, clicks and conversions)
The second level down (the child of a campaign) is Ad Sets. Ad Sets contain the targeting criteria, the placement parameters and budget for each of those. A campaign has one or more Ad Sets.
Each Ad Set is then comprised of one or multiple Ads. Ads are the creatives that are trafficked on Facebook or Instagram.
If you ask a BI tool or Facebook to retrieve the first 100 campaigns currently in your account, the SQL query would be the following:
SELECT * FROM campaigns LIMIT 100
The * donates all columns
The result of this query is a table that returns the first 100 campaigns and all the columns from the campaigns table.
Now, what if you wanted to retrieve all creatives that ran on Instagram, that are video-based, for campaign x. We have two types of queries we can execute:
1- Nest Queries:
A nested query means multiple queries are nested one after the others. The way those queries get executed is from the inside-out, which means the inner query runs first, as the database treats it as an independent query. Once the inner query runs, the outer query runs using the results from the inner query as its underlying table. In layman terms the query first fetches all Ads with the creative_type of “video”, a table is returned containing all the creative with type video. This table is used for the above query, fetching all AdSets for those Ads that trafficked on “Instagram”, return a new table, then filter that table with all the Ads and AdSets that belongs to “campaign x”. This type of query consumes server resources and takes time to execute.
SELECT camp.* FROM (
SELECT adset.* FROM (
SELECT *
FROM ads
WHERE creative_type='Video'
) adset
WHERE adset.placement = 'instagram'
) camp
WHERE camp.campaign_name = 'campaign x';
2- Joins:
SELECT *
FROM campaign c LEFT JOIN adset as
ON c.id = as.campaign_id
LEFT JOIN ads ads
ON as.id = ads.adset_id
WHERE c.campaign_name = 'campaign x' AND as.placement = 'Instagram' AND ads.creative_type='Video'
The second code uses LEFT JOINS to perform the query, although slightly faster and the better one to use. However, it is affected by the volume of data that it is loads every time.
Take the following image as a reference. The graph represent data sources imported into a BI tool, with several relational modeling done between them and the resulting Fact tables with all the dimensions and measures in place.
If we go back to the store business diagram, if you wanted to retrieve all customers along with the product price then the BI tool navigates from the customer's table to the orders table, order items, product and product pricing. This navigation might be ok if this was the only report you're generating, but if you have a dashboard with 20 different reports, it might take the BI tools several hours to display a single dashboard.
However inefficient, OLTP or Inmon ER modelling is still a preferred choice in designing the data model. Inmon states that building a data model begins with the corporate data model. This model identifies the key subject areas, and most importantly, the key entities the business operates with and cares about, like customer, product, vendor. From this model, ER creates a detailed logical model for each major entity. Inmon advocates a top-down design of the model of all the enterprise data using tools such as Entity-Relationship Modeling (ER). ER allow for the Entity/Relationship to represent real-world objects, which mimics business processes.
For example, a logical model built for Customer with all the details related to that entity. There could be ten different entities under Customer. ER captures all the details including business keys, attributes, dependencies, participation, and relationships in the detailed logical model. The design of an ER data model is called a Snowflake. The key point here is that the entity structure is built in normalised form. Normalised data avoids data redundancy (duplication) as much as possible. The normalisation of the data leads to the precise identification of business concepts and avoids data update anomalies.
If OLTP or ER models are not suitable for analysis, what is the alternative?
The alternative is a Dimensional Modeling. Dimensional model is part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball which includes a set of methods, techniques and concepts for use in data warehouse design. The approach focuses on identifying the key business processes within a business and modelling and implementing these first before adding additional business processes, a bottom-up approach.
The Kimball approach to building the data warehouse starts with identifying the key business processes and the key business questions that the data warehouse needs to answer. The principal sources (operational systems) of data for the data warehouse are analysed and documented. ETL software is used to bring data from all the different sources and load into a staging area. From here, data loads into a dimensional model.
The key difference between these two methodologies is that the model proposed by Kimball for data warehousing (the dimensional model) is denormalised. The fundamental concept of dimensional modelling is the star schema. In the star schema, there is typically a fact table surrounded by many dimensions. The fact table has all the measures that are relevant to the subject area, and it also has the foreign (called surrogate keys) keys from the different dimensions that surround the fact. The dimensions are denormalised entirely so that the user can drill up and drill down without joining to another table.
Dimensional modelling advocates the use of summarised tables. A summarised table is a single table that is generated by joining multiple tables during the ETL stage, so a single row contains all the information to describe the dimensions, measures, hierarchy and the grain. One has to be able to see the dimensions and the facts to use them.
Summarised reports are different than a Snowflake approach practised in the Inmon methodology. As the name implies, in a Snowflake approach looking for a dimension/measure requires several reports to be joined to query the data successfully. DM doesn’t mean that you cannot perform complex modelling on the data, there is plenty of data modelling to be done, but rather than creating relationships between tables, you are performing dimensional modelling.
The image below visualises the process of dimensional modelling created using Infor(BIRST) tool.
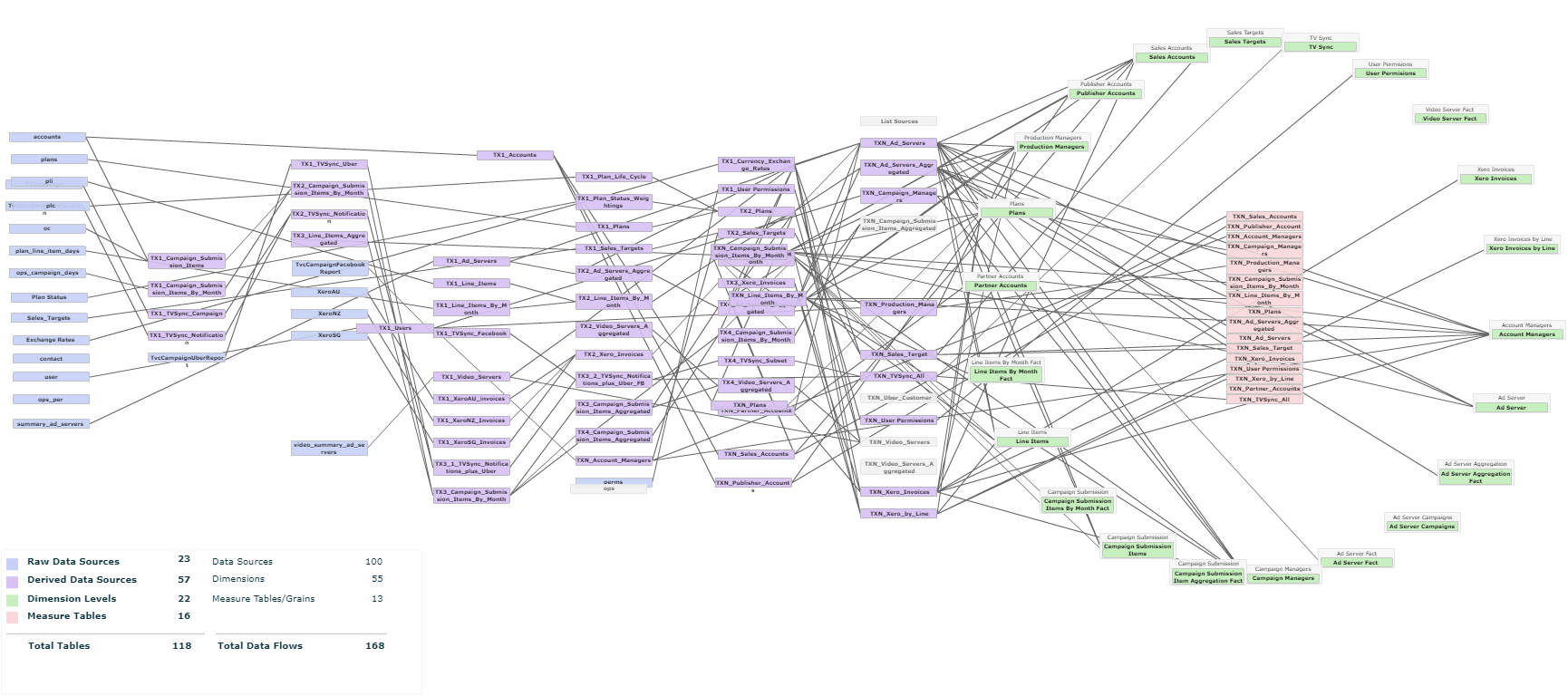
The blue represents the data sources, and the purple boxes represent the joins. The green boxes are the dimensions, while the pink boxes represent the fact table. All queries execute between the dimensions and the fact table. When loading a new dataset then the whole model is updated starting from the blue squares.
Dimensional Modelling is the most supported model in modern BI solutions because it's suitability for analysis.
Load:
A load is a process of writing the transformed or extracted data into the target database or Data Warehouse. There isn’t much to the loading processes beyond recording the extracted data and the transformed records into one or several databases based on the data model design. We'll discuss the design of the data warehouse in the following section.
ETL is a costly and time-consuming process to implement. The length of the implementation and the cost is dependent on
The data sources extraction scripts
Transformation scripts on the extracted data
The final data model
The programmers will most often than not create a Web application to manage and monitor the ETL process. ETL is written to run periodically, thus requires the implementation of a web application that monitors ETL executions and flag any failed scripts to remedy those failures.
The cost of the ETL implementation can go from a couple of thousand dollars to tens of thousands of dollars, and can also go on for 6 months or more before starting the BI tool implementation. You can employ several development methodologies (e.g. Agile, Waterfall or Rapid Development) simultaneously develop ETL scripts while implementing the BI tool.
The overall cost of the ETL is broken down into three components:
Cost of implementation: This is the cost directly associated with the time required to develop the ETL scripts and the cost of the in-house team or the agency.
Server Costs: ETL scripts or the ETL application runs on a server or several servers. The server adds to the ongoing cost which needs researching early in the BI tool implementation budget. Again there is no magic number here, it all depends on requirements, team and the technology used to develop the scripts.
Maintenance and Servicing: This is an often overlooked piece of the pricing, especially with companies with no prior experience in a development project. In practice, things break, especially in web applications. There are many reasons why ETL breaks, thus require servicing again:
API changes: We’ll be discussing APIs in more depth later in this guide, but suffice to say that cloud applications tend to improve on their API often as they release new features or fix bugs in their application. The schedule varies from one application to another, and in some cases, they don't advertise those changes beforehand. In such cases, the ETL scripts connecting to the API will most probably break. Therefore requiring updates to the ETL script to accommodate the changes in the API.
Servers issues: The servers hosting the ETL scripts or application sometimes break. This break can happen for any number of reason that fall beyond the responsibility of your company, or the team developed it. It can result from a cyber attack on the hosting company, an automatic update that was rolled out on the servers that broke functions in the ETL application or just a patch that was implemented by the hosting company that broke something in the ETL code.
Code updates: The ETL applications might be using 3rd party services or code (called either components, frameworks or plugins) that updates automatically to update the framework or patch bugs found in the previous version. Depending on the architecture of the ETL application, if those code updates happen outside the control of the server then most often than not the ETL breaks.
To mitigate the risk of having the ETL scripts failing the business, a Service Level Agreement is required, which describes what is the agency responsible for after delivery of the ETL stage. The SLA needs to cover:
What does the SLA cover? (e.g. are bugs resulting from the code developed is covered in the SLA or not)
How often are those services carried out? (is it a monthly schedule, quarterly, half yearly or ad-hoc)
The cost of the SLA
What happens if the business wishes to sign an SLA with another agency or perform the support in-house?
Having a clear understanding of those issues early on in the processes goes a long way to control the time and budget of the ETL phase and mitigate the risk of deadlines and costs spiralling out of control.
Developing and maintaining an ETL layer is one of the most significant barriers for many businesses in adopting an insight-driven approach to managing and growing their business. The prospect of needing to spend tens of thousands of dollar upfront on top of the BI tool cost itself is frightening, add to the fact they’ll need to wait for 6 months or more before getting any insights into the business puts a BI tool on a some-day, one-day wish list but not as a priority.
Luckily this is a problem not only for businesses who wish to adopt BI in their business, but it’s also a common problem for many BI vendors as well. The solution that is widely adopted in the BI industry today is to try to eliminate this barrier. The current solutions in the market are one of the following:
Building direct API connectors to favourite data sources (Extracts and Loads)
The inclusion of Transform tools inside the BI tool to manipulate the data.
A BI tools that offers both data connectors and ETL tools.
The creation of data connectors goes a long way in reducing the cost of BI implementation, it also has a significant impact on the implementation time required to bring data into a BI tool for analysis, in fact, it allows immediate data modelling and analysis.
So does this mean that ETL layers are no longer needed? Far from it. To understand why that is, we’ll need to discuss an important topic, APIs.
What is an API
In computer programming, an application programming interface (API) is a set of subroutine definitions, communication protocols, and tools for building software. In general terms, it is a set of clearly defined methods of communication between various components. As such an API is either a way for various components of the application to communicate together (internal) or to give access to an external source to communicate with the application (external). API means that as a regular user interacts with an application through the use of a mouse, keyboard, browser and visual aids (e.g. forms or web pages). A programmer can have access to the same application and interact with it through subroutine definitions and communication protocols programmatically without opening a browser.
This distinction is crucial as it paves the way to understand how a software company builds APIs:
API is another interface to the application, in most cases, it takes the same amount of time to build an API for programmers as it does to build a user interface for the end users.
There is no revenue in building an API, at least for businesses that don’t include API as a core business model for revenue. As such, any software company have to weigh how much-dedicated resources to building an external API as opposed to in building features to the software and servicing regular users. The result of that decision might be an API that offers little functionality or access compared to using the UI of the application.
Most API’s sucks, this is a fact. When building a User Interface to a user, a developer and a designer have a wealth of User Experience (UX) principles that help in building a practical application, and there is also a wealth of libraries to help in building a pleasing UI which includes drop-down menus, forms, scrolling lists. Unfortunately the same cannot be said about APIs. There are a few specifications that a developer can adhere to (e.g. SOAP or REST) when designing an API. However, even with those specifications, the implementation relies heavily on the end developer, and that usually comes out like a science experiment that went wrong at best or a mid-night brain fart in worst cases. Examples of horrible API designs are:
Complex API authentication mechanism that feels like a cross fit session.
Many and many API calls that need to be made to get simple information back.
A lousy API is a universal problem, and it’s not limited to smaller software, it is widely found in well-established software as well. Unless the software company have given the same attention and focus on the API part as it did on the UI part, the results are more often than not is an API that is horrible.
Some API’s provides almost near access to the underlying software, which results in having hundreds of API calls that need to connect one after the other to retrieve a single piece of information. This type of API forces the developers to replicate the application database design with all the associated logic, which is time-consuming.
API’s change periodically, most software companies don’t bother advertising those changes beforehand to notify anyone using the API of pending changes. A few years back we wrote an API connector for a prominent Advertising platform, within an 8 months period, the company kept on changing the column names. We knew about those changes when the ETL connection failed.
For those reasons building a Data Connector through an API is a time-consuming process, which requires several developers labouring together to build a single data connector and maintaining updates.
The point of all this is the following: For a BI vendor that is licensing their BI tool for $50, $200 or even $500 monthly, which also includes a 100 connectors ore more, it is not economical for the vendor to build a connector that covers all API points. Instead, the common practice is to write an API connector that covers a small percentage only.
What dictates the right percentage? It’s called most common uses. The definition of most common uses is blurred at best and differs from one BI vendor to another. Generally, though it can be broken down to:
Target market: If the BI tool is targeting the finance and accounting industry then the BI tool includes connectors to most common accounting and finance software used by that market, and the API covers common use cases of that market. On the other hand, if a BI tool is targeting Online Marketers, then the connectors expand on the API calls for marketing software but offers basic connectivity to accounting software. Common use cases data connector usually cover as low as 20% up to 60% of the overall functionality of the particular software.
Type of analytics: Does the BI tool offer historical analysis of the data? Alternatively, is it more about the current time and performance side of analytics? Answering this question results in a connector giving you access to all of the required data for analysis. However, it might fall short on the historical aspect, as it retrieval for older transnational data older than 6 months are ignored. Again this is due to economics. Databases are expensive, and it doesn’t make financial sense to give a company access to a DB that dumps millions of records for each connector while charging them a couple of $10 or $50 per months. It might make sense if the BI vendor has only 1 customer, but a 1000 customers all sharing the same resources it doesn’t, as such BI tools limit how much you can store per account and how much data your allowed to retrieve per connector.
When evaluating a BI tool based on the connectors, take an interest in understanding what each connector offers beyond that the connector is present. Compare the data that can be retrieved and historical limit against your business needs before making a decision.
Are Data Connectors useless? The answer is No. Data connectors allow for fast deployment, and it can cut down on implementation costs significantly, so they are useful in that sense. Another factor that makes data connectors very useful is the intended use of a BI tool. If your business needs are immediate and you are in an industry where actions or decisions are made based on real-time data insights, then a data connector that does offer that level of detail is more suitable for your current and ongoing business needs.
Data connectors can also be used along ETL layers, either to retrieve data for the ETL layer or as another data source for the BI tool. You don’t need an ETL layer for every software your company uses, and there might be applications that the businesses use occasionally. In this case, use a data connector for those applications and an ETL layer for the ones that need a custom and detailed data.
In other cases, some data connectors provide 80% of the functionality needed, build the remaining 20% through an ETL layer. It's still a huge win, as 80% of the requirements and the implementation is there already.
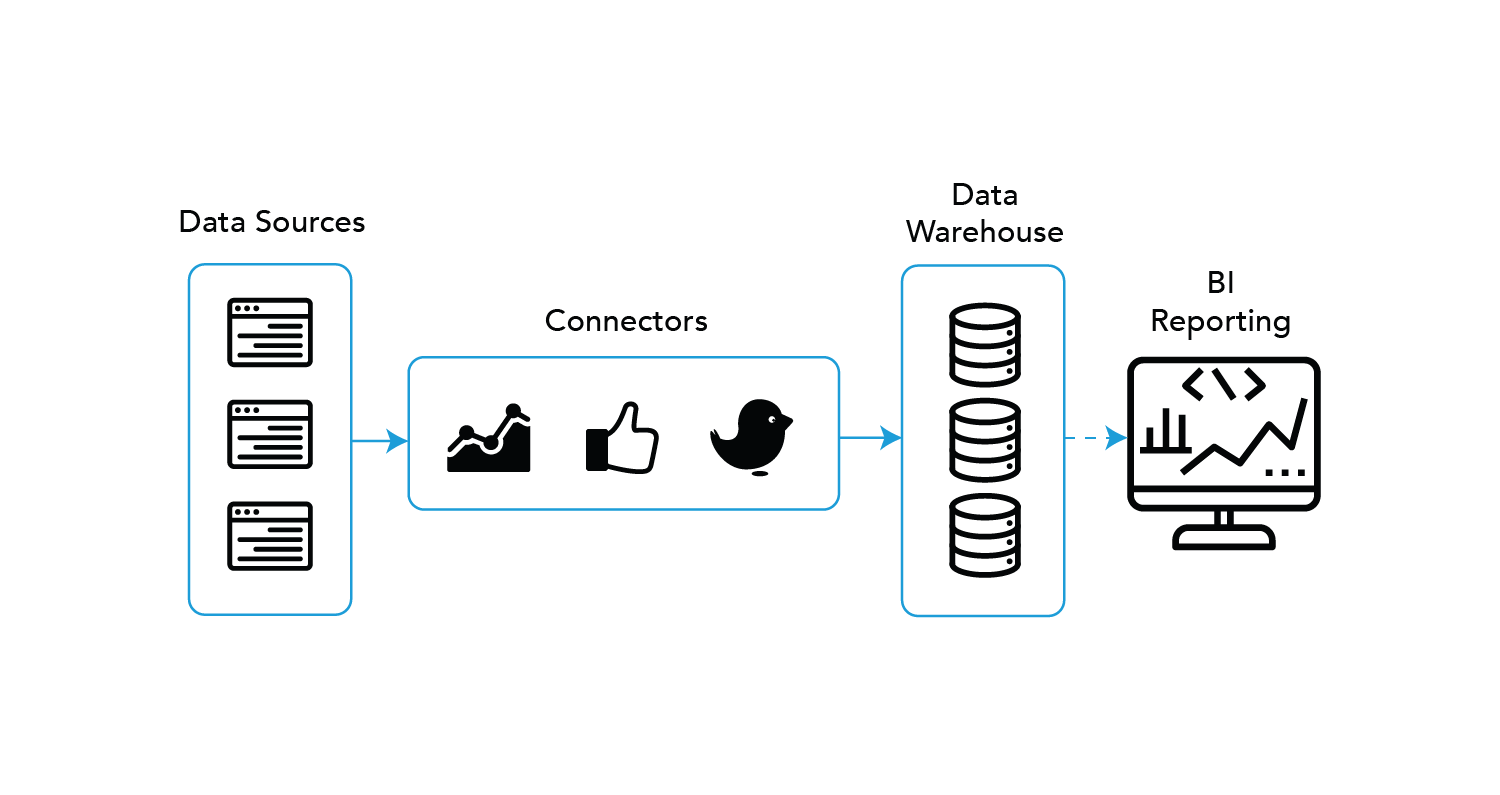

You can expect two types of data connectors in the market. Built-in data connectors, we’ve covered those above, and Stand-Alone data connectors.
Stand-Alone data connectors offer better integration with the applications, that's because the company building those connectors focuses on developing and selling those connectors. So it is in the best interest of the vendor to have an API connector that is as thorough as possible. Stand-alone connectors runs locally, hosted remotely by your business, or on the cloud. The cloud option is more expensive than having the connector alone. Most connectors need data storage to store the retrieved data as well, which is an extra cost.
Stand-alone data connector offer connections to popular databases and data warehouses as well, and some allow for direct integration to certain BI tools.
There are many choices when it comes to extracting, transforming and loading data into a BI tool. If you’re an individual, start-up, small or medium business, starting with a direct data connector, moving to a stand-alone connector and then custom built ETL layers is the best path to take. If you’re a medium business or a large enterprising that already uses database and DW to store their data, then an ETL layer gives you a better approach.
Data warehouse (DW) or (DWH) is a vital component of a BI tool. So in most cases, it is the second component of an ETL stage. A DW is the storage place for your data models, OLTP or OLAP. It's also:
A giant storehouse for all your data.
DW acts as a central repository, aggregating data from multiple systems. Combining data in this fashion allows you to create reports and analysis that spans multiple systems in your organisation.
Additionally, a DW typically represents a single source of truth (SSOT). It is considered the most accurate version of your data.

A data warehouse exists as a layer on top of another database or databases (usually OLTP databases). The data warehouse takes the data from all these databases and creates a layer optimised for and dedicated to analytics. OLAP accommodates data storage for any number of applications, and one data warehouse equals infinite applications and infinite databases.
So what are the critical difference between an OLTP database and an OLAP DW?
Most databases use a normalised data structure. Data normalisation means reorganising data so that it contains no redundant data, and all related data items are stored together, with related data separated into multiple tables. Normalising data ensures the database takes up minimal disk space while maximising response times. As we’ve previously illustrated in the ETL stage, the more normalised the data is, the more complex the queries needed to read the data because a single query combines data from many tables (snowflake). Snowflake puts a massive strain on computing resources.
The data in a data warehouse does not need organisation for quick transactions. Therefore, data warehouses usually use a denormalised data structure. A denormalised data structure uses fewer tables because it groups data and doesn’t exclude data redundancies. Denormalisation offers better performance when reading data for analytical purposes.
Analytical queries are much easier to perform with an OLAP database. An OLAP data warehouse allows semi-technical users (anyone who can write a basic SQL query) can fill their own needs. The possibilities for reporting and analysis are endless. When it comes to analysing data, a static list is insufficient. There’s an intrinsic need for aggregating, summarising, and drilling down into the data. A DW enables you to perform many types of analysis:
Descriptive
Predictive
Prescriptive
Data warehouse offers unique ways to processes your data models, which optimises for analysis. DW achieves this by different storage capabilities offered by a data warehouse. OLAP data models stored best as cubes. Often referred to as OLAP cubes. An OLAP cubes contains dimensional attributes and facts, accessed via languages with more analytic capabilities than SQL, such as XMLA, MDX or DAX. OLAP cubes are often the final deployment step of a dimensional DW/BI system or may exist as an aggregate structure based on a more atomic relational star schema.
OLAP cubes are multidimensional, The Multidimensional database is a very different structure than a relational database and allows us to generate reports very fast. The Multidimensional model was the only solution in the past to create multidimensional databases. Today modern DW/BI solutions support Tabular models.
The Tabular model uses a different engine than multidimensional, and it is designed to be faster for queries based in columns. Because Tabular uses columnar storage (multidimensional models use row storage) that offers better data compression. Data storage happens in-memory, often referred to in-memory analytics, so it is imperative to have lots of memory in your server and high-speed CPUs. The disks are not as crucial in a Tabular model.
What are some of the differences between tabular models and multidimensional models?
Tabular Models:
Easier for understanding and creating the model.
Queries on columns execute faster than multidimensional cubes
Tabular is a memory dependent solution, and more memory ensures better performance, as opposed to multidimensional cubes which is disk dependent.
Data comparison is more efficient and consumes one-tenth of the size of the original database, whereas the compression of multidimensional is a third of the size of the original database.
Multidimensional Cubes:
If your working with a large amount of data, even terabytes, it’s better to go with the multidimensional database. In fact, if your database requires more than 5 terabytes, multidimensional is the only option.
Multidimensional cubes scales and performs better than tabular.
Some aggregations function or actions support is limited to the multidimensional model only
In case it hasn't dawned on you yet, DW is an integral part of BI tools, in fact, a BI tool relies heavily on the existence of a DW, as it determines the breadth and depth of a BI tool. I would even categorise a BI tool as an interface for a DW.
When comparing BI tools, the main difference in pricing comes down to the inclusion of a DW in the BI tool. A $1,000 BI tool might be comparable in features to a $150,000 tool. The difference is the $150,000 tool includes ETL and DW as part of the solution, while the $1,000 requires you to build the ETL and DW solution yourself, which costs the same or more.
Most entry-level BI tool doesn’t require DW as a requirement, in such case analysis is done on an OLTP database. Because of the number of tables joins in an OLTP database, performing analytical queries is very complicated. They usually require the expertise of a developer or database administrator familiar with the application. Reporting is typically limited to more static, siloed needs. You can get quite a bit of reporting out of an OLTP database, for example, you might generate a daily or monthly report of a campaign conversion or a list of list of site visitors by source. These reports are helpful, particularly for real-time reporting, but they don’t allow in-depth analysis.
BI is notoriously difficult to implement, often taking six months, a year or more. That complexity of implementation often sits with the Data Preparation stage and the actual DW/BI modelling stage. The Data preparation stage continues to be a time-consuming process because of the volume of work needed in combining, cleaning, and shaping different data sets into a clean and structured data that can model in the DW/BI platform.
Data Preparation is the process of collecting, cleaning, and consolidating and data modelling the data into one file or data table, primarily for use in analysis. The Data Preparation layer is optional, and it depends on the business data sources and the BI tool.

Some high-end BI tools offer modelling tools inside the BI tool. The absence of such a tool means the performing data modelling during the ETL stage and the Data Warehouse design, which means relying on IT to perform data modelling, two issues here:
Developers are not business savvy and don’t possess any strong business acumen to address business problems.
Any changes required on the data processor happens in the code, so if there were an outlier in some of the data, this would require the developer going into the database and run scripts to fix those outliers or worse writing a script to the ETL layer.
As such, the data preparation processes are better suited for business analysts.
The Data Preparation layer is usually a manual process that the business implements, done through a 3rd party service. A business can choose to write their Data Preparation solution because they have the means to do so and it might prove to be more financially economical to do so. So the cases vary depending on the business situation.
The traditional way in performing any data cleaning has always relied on the use of spreadsheets, which involved exporting the data from the database to a spreadsheet, running functions or scripts on the exported data from a spreadsheet system, and then importing the data back into the database. Thankfully many 3rd party solutions offer much better control of the processes.
Why can’t the BI tool perform manual changes to the data if it already has direct access to the data warehouse? A BI tool never adds, changes or deletes any part of the underlying data, opening the door to such functionality is a scary prospect.
The need for the Data Preparation arises from many factors, and there isn’t a single use case to group those use cases. However, we can outline the most common ones below:
Outliers: In statistics, an outlier is an observation point that is distant from other observations. An outlier may be due to variability in the measurement, or it may indicate an experimental error. The real world your data might have outliers due to many factors (e.g. user input error or data export error), once present they are annoying and throws the whole analysis. Let’s look at a simple example: The accounting department records all product dales as they happen in the system, one of the products had accidentally 2 or more zeros added to it. At the time of running the reports, the data looks odd in a particular day, which affects the week, month and quarter. There are three traditional solutions:
Asking the accounts departments to fix the error in the system, and run the ETL stage manually, which means there is an assumption ETL layer picks the change and update the record, however, this is never always done. A developer cannot account for any change in a record when writing the ETL, and it’s just time-consuming.
In case the ETL cannot handle the changes, asking the developer to write scripts to handle the changes.
Having the business analyst direct access to the data warehouse and performing the change manually through SQL.
Missing data fields: Your business staff might enter all the vital information but not every piece of detail that is needed, the result is having a lot of missing data that results in inaccurate analysis. For example, missing State or City fields.
Naming conventions: This happens when grouping or identifying fields are named differently from one record to another, this use case is universal in the absence of a strict naming convention in the business. For example, an advertising agency wanting to perform analysis on the different campaign targets, the problem is that the targeting field for each campaign is random, some users where typing L1, L2, L3 to identify the field, other instances it was named L1_M_QLD, or Male demographic - Brisbane. The choice was either for someone to go manually into hundreds of thousands of records and change each of them manually or perform data cleanup on the records in an automated way.
Free-Form text fields: Some software allows for free-form text fields anywhere in the records. I know! An example of this is one company that had a bespoke booking system built by a software agent, the agency decided to use free-form text fields for all data inputs, believe it or not, the users of the business found a half dozen ways to type Australia alone.
Obscure column names: This means the field name from the software interface is different than the exported record. Obscure column names are more common than you might think. For example, one software that sends out Newsletters to subscribers, the business had created custom fields for different targeting, the exported data listed those fields as “Additional Field 1”, “Additional Field 2”. Another example is a CMS platform that allows for custom fields and even custom objects. The business had created 50 plus custom fields, adding new columns, each column was exported as f1, f5, f22, f7, yes the numbers were not sequential, and the custom objects had 6 digit random identifiers.
Those kinds of issues are enormous time wasters. Unfortunately, they don’t happen once, and they are repetitive and random. Not every business has the means to provide a long-term solution, which usually tend to be is costly for the business as they’ll have to get the developers involved to make changes in code which ultimately introduces bugs in the process in the ETL stage. For most cases implementing a data preparation processes is faster and cheaper.
Ch5. Required Resources
The third part of a BI implementation involves the resources (or talents) that are going to be implementing the solution and driving it forward. These resources attribute to the initial and ongoing investment of the BI solution and need to be taken into account as early as possible.
In this section, we'll be listing the skills needed for the implementation and management of a BI solution, broken between the development and analytics department. Some organisations tend to have many role verticals in the business, however for most businesses the skills list in this section is talent requirements to get the job done.
- Ch5.1 Development
- Ch5.2 Analytics
Development
5.1.1 BACK-END DEVELOPER
A back-end developer is a programmer who is capable of building the logic and architecture of web platforms and web services. A full-stack developer adds the ability to build the front end side of the web service as well, and some senior full-stack developer can also develop mobile apps.
Stage in the pipeline: ETL stage and Data Warehouse
Seniority required: Mid-Level to Senior
Expected annual salary: $110,000 - $150,000
Technical Requirements:
- Strong web development architecture (Objective Oriented or Functional)
- Strong design patterns (preferably MVC)
- Strong Microservices background
- Strong API development knowledge
- Good understanding of MySQL, PostgreSQL or even SQL.
5.1.2 SOFTWARE ARCHITECT
A software architect is a software expert who makes high-level design choices and dictates technical standards, including software coding standards, tools, and platforms.
Stage in the pipeline: ETL Architecture and Data Warehouse design
Seniority required: Senior
Expected annual salary: $150,000++
Technical Requirements:
- Server design experiences
- Strong application deployment experience
- Strong experience in multiple web development frameworks
- Background in DevOps
5.1.3 DevOp
DevOps (a clipped compound of “development” and “operations”) is a software engineering culture and practice that aims at unifying software development (Dev) and software operation (Ops).DevOps increases an organisation’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organisations using traditional software development and infrastructure management processes.
Stage in the pipeline: ETL Architecture, Data warehousing and BI Servers
Seniority required: Senior
Expected annual salary: $200,000++
Technical Requirements:
- DevOps Release & Delivery experience
- Deep knowledge of Continuous Integration / Continuous Delivery
- Deep knowledge of DevOps best practices
- Deep understanding of Entire Application Development Life-cycle
- Strong server management and deployment background.
2. Analytics
5.2.1 DATA ANALYST
Data analysts translate numbers into plain English. Every business collects data, whether it’s sales figures, market research, logistics, or transportation costs. A data analyst’s job is to take that data and use it to help companies make better business decisions.
Data Scientist duties typically include creating various statistical analysis, data mining, finding correlation patterns and identify causes for business-critical metrics.
Stage in the pipeline: Data Analytics and BI Reports
Seniority required: Mid to Senior
Expected annual salary: $150,000++
Technical Requirements:
- Sound data management experience
- Sound communication skills
- Ability to generate insights and present solutions/recommendations to a variety of stakeholders with varying technical capabilities
- Sound SQL and Visualization (Tableau) experience
5.2.2 DATA SCIENTIST
A Data Scientist is someone who makes value out of data. Data scientists analyses data from a different source for better understanding of how the business performs, and to build AI tools (i.e. prediction models) that automate certain processes within the company.
Data Scientist duties typically include creating various Machine Learning-based tools or processes within the company, such as recommendation engines or automated lead scoring systems. People within this role should also be able to perform statistical analysis.
Stage in the pipeline: Data Analytics and Predictive Analytics
Seniority required: Mid to Senior
Expected annual salary: $170,000++
Technical Requirements:
- Strong stakeholder engagement, requirement elicitation and solution presentation abilities.
- Data Science experience is building a range of statistical models relating to customer marketing strategy (Acquisition, retention, growth, cross-sell, churn), customer segmentation, next best action, campaign analytics.
- Strong technical skills using SQL/NoSQL or Python or R to extract, manipulate and merge large volumes of data from disparate source systems
- Exposure to BIG DATA platforms with technologies that include; Hadoop, Apache Spark, Scala, PIG, Hive.
5.2.3 REPORTING DEVELOPER
An integral member of any BI team, the BI Reporting Developer is responsible for the design, development, implementation and support of mission-critical Business Intelligence (BI) reports.
Stage in the pipeline: Data Preparation and BI Reports
Seniority required: Senior
Expected annual salary: $200,000++
Technical Requirements:
- Ability to build, implement and support BI Reports.
- Strong data integrity issues like manipulation, validation and cleansing
- Robust data analysis to understand business requirements, design, deploy and test the reports
- Good experience in BI implementation methodologies
- Strong analytical and problem-solving skills
- Good knowledge of relational databases and mapping
The annual salary estimates are based on the Australian recruitment market, presented here as a means to weigh the cost of hiring versus outsourcing a specific part of the implementation processes.
A business might require one or several resources in each department, how many are required depends on the business needs and volume of the work required. It is not uncommon to find a single resource that can perform the role of two or more in a single department. However, they are expensive and not easy to find. Finding a well-versed someone in the development and analytics fields is unusual, and if your business happens to find one, do everything you can to hire them and to keep them as they're scarce.
Ch6. Business Inteliggence Helpers
ETL, DW and Data Preparation Tools
Before diving into commercial BI tools, we'll explore what we call helper tools. Helper tools are solutions provided by vendors to tackle the back-end implementation of a BI or an Analytics solution. These helper tools allow a business to bypass the traditional way of implementing an ETL stage for instance, or a DW design, and even a data preparation stage.
- Ch6.1 ETL Helpers
- Ch6.2 Data Preparation Helpers
- Ch6.2.1 Paxata
- Ch6.2.2 Tableau Prep
ETL is a significant roadblock for any BI implementation, and naturally, there is a market that is eager to find tools that help with the implementation or ease the process altogether. The following commercial products each tackle different parts of the ETL processes and offers their unique tools to solve it.
Microsoft SQL Server is an enterprise relational database management system. As a database server. MS SQL Server is one type of relational databases. Other known types are MySQL, Oracle, Postgres and Informix. If your company uses MS SQL servers or plans on deploying applications on MS SQL servers, then you’ll have access to three powerful tools to help you in the design, modelling and reporting of your SQL database. These tools are:
SQL Server Integration Services (SSIS)
SQL Server Analysis Services (SSAS)
SQL Server Reporting Services (SSRS)
SSIS is an ETL and a data modelling solution used to perform a broad range of data migration tasks, such as data integration and workflow applications. It features a data warehousing tool used for data extraction, transformation, and loading.
SSAS is the technology from the Microsoft Business Intelligence stack, to develop Online Analytical Processing (OLAP) solutions. In simple terms, you can use SSAS to create cubes or tabular models, using data from a data warehouse for more in-depth and faster data analysis.
SSRS is a server solution that deploys on company on-premise servers for creating, publishing, and managing reports, then delivering them to the right users in different ways, whether that’s viewing them in a web browser, on their mobile device, or as an email in their inbox.
Microsoft is a leading provider in the DW/BI space, offering solutions for Traditional and Self-Service BI (more on that topic later). MS doesn’t only provide tools for DW/BI solution, it’s also a significant contributor in this field, having created two staple languages for data modelling and querying of tabular and multidimensional cubes (MDX and DAX). These languages are widely used in major DW/BI solutions. So it’s natural MS would be offering a host of tools that support ETL solutions, data modelling and reporting.



SSIS is a powerful tool for creating ETL workflows and also designing data models (ER or DM). It offers a visual interface for visualising the ETL workflow and supports coding for a finer grain of control. You can control the flow of workflow by dividing the elements into:
Containers that provide structures in packages
Tasks that provide functionality
Precedence constraints that connect the executables, containers, and tasks into an ordered control flow.
Pricing of an SQL Server varies on the needs of the company. MS offers a wide range of pricing to meet every business size and team. In the lower MS offers a community edition of SQL server, suitable for those who want to learn deployment and implementation of an enterprise level DW/BI platform. On the high end is the enterprise license which costs $14,256 per CPU core. However this is not the only price, other elements come into play, To give you an example of a typical SQL server pricing, let’s assume the following parameters:
One Host or computer instance
2 CPU
8 Core per CPU
5 virtual machines running SQL
4 vCPU per VM
This configuration type typically costs $114,048 if pricing performed per core or a $142,560 based on VMs.
Xplenty is a web platform that allows a business to use it’s platform to:
Connect to many data sources and databases through built-in connectors to retrieve all the required data
Developing transformation logic using a drop-and-drop visual interface
Monitoring of ETL jobs web services (e.g. if a web service fails you get notified and restart it)
Cloud server scalability and uptime monitoring

Xplenty offers more than a 100 data connectors (integrations) which covers a wide range of services with more being added to the platform periodically, either because a customer requested it or it’s in the platform road-map.
Xplenty pricing starts from $999 monthly for a few ETL jobs per day and $2,499 monthly for continuous updates per day. Pricing increases with data volume, and the server instances required. Considering the cost of the custom ETL integration and running server costs, Xplenty might prove a better solution for your business.
Having said that Xplenty doesn’t provide data storage, you needed to be set up and deployed a database or data warehouse that can be connected to Xplenty to load the result of ETL jobs.
CADAT provides direct data connectors to many popular cloud applications and databases in several forms, the form options provided are:
Open Database Connectivity (ODBC) driver
Java Database Connectivity (JDBC)
Microsoft SQL Server Integration Services (SSIS)
MuleSoft
Microsoft Excel
Microsoft Power BI Desktop
any many more
CDATA connectors are purely an extraction service. Transformation happens by the user after extracting the data. When used with MS Power BI, for instance, the connectors load as an internal data source, which allows for data modelling and transformation within Power BI, and can also give access to DirectQuery, so data loads are direct from the database, rather than cached data.
CDATA supports an excellent option for many or all of the data connectors required by a business, The Extraction from an ETL service is the most time consuming to perform and get it working right so this option is a huge time saver and an effective way to cut down ETL costs.
CDATA plans are generous, any destination (ODBC, JDBC or Power BI) connectors sells for $399 for up to 60+ connectors or a $599 for 100+ connectors. The licensing is yearly.
Workato is a cloud solution that provides API level access to most platforms in the market in the form of triggers and actions. This type of integration is currently dubbed Integrated Platform as a Service (IPaaS). There are three benefits of using Workato or any other IPaaS service.
The data ETL job is activated only when a trigger is activated, for example, when generating a new invoice from accounting software.
There are no server costs to worry about, and all failed jobs are flagged to be investigated or to try-run another time.
Workato does the API maintenance and connectivity, so any API changes are taken care off.
The biggest drawback of Workato or similar IPaaS tools is
The number of Data Connectors available
The number of API endpoints implemented. This feature differs from one data connector to another, the majority of connectors are usually simple and allow simple triggers (e.g. new invoice, new user) and simple actions (e.g. search invoice, update user)
The type of transformations one can perform on the data is limited. Again each IPaaS platform provides a different level of transformations that you can perform on the data.
Workato pricing starts at $599 monthly on an annual commitment for basic apps and $2,499 monthly with an annual commitment for business plus apps.
Zapier is perhaps more popular than Workato, but offering the same service but with the different pricing structure. Concerning Data Connectors, Zapier offers the biggest integration library from all similar IPaaS. Zapier is non-discriminating when it comes to the type of data connectors it offers, and perhaps that’s where it falls short for some people, as the majority of the connectors are simple, with complex integration subject on the data source vendor willingness to participate in building a better connection with Zapier. As such you might find yourself looking for an IPaaS service that is specific to your industry, as they’ll have better triggers, actions and transformation for the desired apps.
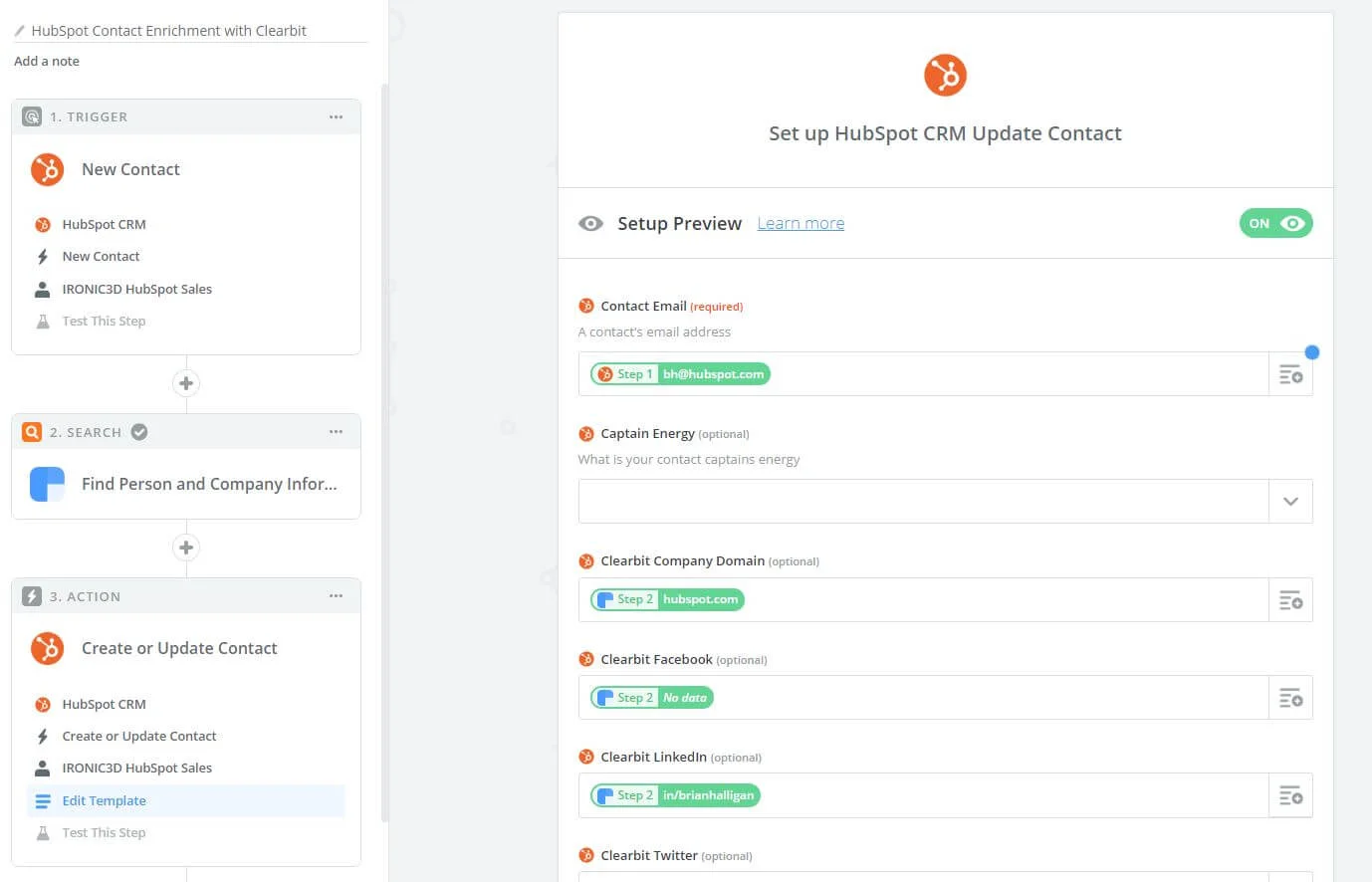
Zapier pricing is more flexible than Workato. Starting FREE for 2 data connectors (Zaps) that update every 15 minutes. $20 per month for 20 Zaps and multi-step zaps which update every 15 minutes, or $50 for 50 zaps every 5 minutes, and so on.
Each of the above tools offers a percentage of the overall ETL solution you’re business might need, so why would you choose an IPaaS over a custom ETL, or custom ETL over a visual ETL service, the obvious answer is cost and time. Building a custom ETL solution is an overkill, unless your business has the means and resources to build it and maintain, or if the ETL solution your business is building is to commercialise at a later stage. However, for a business that is interested in having a BI solution with many data sources, assembling a solution that contains parts of a custom ETL layers, commercial ETL layers, data connector or IPaaS is the best approach.
For example, a 25+ data source ETL solution we've built for a company was broken down to the following components:
Custom ETL layer that covered 90% of all the data the business uses on a regular basis.
8% were done by a simpler ETL that uses spreadsheets placed on a cloud bucket or uploaded manually by specific users of the business users, and these were data sources that were not used regularly and in sometimes are used ones.
The remaining 5% we used an IPaaS service instead, this way to capture details from new invoices generated and to store the data in the data warehouse.
The above solution was more cost effective than trying to build the remaining 10% by code, it saved the company 4 months of development and in continuous costs.
As outlined in the Data Preparation state, data preparation is common practice and in some cases a much-needed one. New tools for managing data preparation emerged in the market the past few years. These tools range from data cleaning all the way to enable data modelling, which is an advantage if the BI tool you’re using doesn’t offer any data modelling. Also, you don’t want to spend tens of thousands of dollars to perform data modelling in code. Below we’ll discuss two popular options in this field:
Paxata is a Data Preparation services on the cloud with some AI components. The data preparation on the cloud allows a one more business analysts to comb through all the data in the data warehouse or even directly from a connected source and prepare this data for consumption by a BI platform, catalogue it, version it and secure aspect of it.
Paxata offers a Self-service data preparation that allows non-technical users such as data analysts or power users perform all aspects of data preparation, by providing a visual, interactive interface with built-in algorithms to help profile or join datasets, self-service data prep tools empower end users to perform these tasks by themselves and not have to rely on scarce IT resources.




Paxata caters to the enterprise market with vast volumes of data that requires the use of visuals and machine learning to build an automated process. Paxata pricing starts at $20,000 yearly for 10 Million rows of data to process.
Tableau Prep is a brand-new product from Tableau designed to help everyone quickly and confidently combine, shape, and clean their data for analysis.

To begin with, Tableau Prep costs $70 per month, and it’s part of the Tableau creator offering, which includes Tableau Desktop, Tableau Server or Online. Tableau Prep tightly integrates with Tableau Desktop. However, you can use Tableau prep with any database. Don’t let the price fool you though, this tool bags a lot of punch for that price and it’s more than capable in handling any data preparation job you throw at it.
If you want to edit a value, you select and directly edit. Change your join type, and see the result right away. With each action, you instantly see your data change, even on millions of rows of data. Tableau Prep gives you the freedom to re-order steps and experiment without consequence.

Use smart features to fix common data prep challenges. Tableau Prep employs fuzzy clustering to turn repetitive tasks, like grouping by pronunciation, into one-click operations.
Tableau prep is an indispensable tool to add alongside the BI tool you choose, as with Tableau Desktop when introduced 10 years. Tableau Prep brings enterprise-level data preparation capabilities to SMBs.
Data preparation continues to be a much-needed stage for any DW/BI solution. More and more vendors are starting to develop solutions to ease this process. Your business can continue using Excel for data preparation, however, be mindful that doing data preparation this way is limiting your capabilities to perform more insights and analysis, as the time needed to export, clean, and import back into a DW is a lengthy process.
Ch7. Business Inteliggence Tools
COMMERCIALS PLATFORM CHOICES
In this chapter, we'll explore the different types of BI tools. We'll also list a few commercial BI solution. This list is by no means an exhaustive list. They are BI tools we've used in our business and implemented them many of our clients and keep recommending. It doesn't mean that these tools are the best either. Instead, this list outlines the different BI solutions in the market, both end of the spectrum, and should guide you in evaluating solutions you're currently looking into for your own business.
- Ch7.1 Self-Sevice BI vs Traditional
- Ch7.2 DataBox
- Ch7.3 Tableau
- Ch7.4 Microsoft Power BI
- Ch7.5 Infor(Birst)
- Ch7.6 Salesforce Einstein Analytics
BI tools are broken down into either Traditional BI or Self-Service BI.
We say Traditional BI because since BI solutions introduced first, and up until recent years, BI tools operated the same and required the same amount of investment and resources. Traditional BI solutions were built to satisfy Enterprise companies. Companies that store a massive volume of data on-premise (centralised BI) along with a fleet of IT department to design, model and generate reports for the business. Traditional BI meant an IT team builds all BI reporting and analysis. As such, any updates or request for new reports and insights were done by the IT team as well. This type of process is slow inflexible and Time-consuming.
However, In recent years a new wave of modern BI solutions entered the market, called Self-Service BI which promised to take the implementation out of the hand of an IT department and into the hands of Business Analysts.
Which type is better for your business?
Unfortunately, there aren’t any easy answers for this. Self-Service BI allowed more businesses to adopt and implement BI in their business by lowering the cost and speed of implementation in every aspect of the deployment process. However, Traditional BI is still relevant and required for some businesses.
Traditional BI offers a controlled BI environment. When you control the data and the BI application, you have a chance of controlling the quality of the results. IT departments concerned about quality (as every conscientious IT department should) can make sure that data is properly prepared, stored, and secured. They can build systems that offer standardised, scalable self-service reporting, and they can give users answers to their business questions. Of course, those answers may take a little time to materialise, especially if the IT department is busy with other projects.
On the other hand, Self-Service BI appeal to companies through their simplicity and affordability, and we’re not just talking about spreadsheets. Self-service BI has made giant strides to get to a point where users can access data from different sources, get insights from all the sources altogether, and make faster business decisions. The tools are typically intuitive and interactive (those that aren’t, tend to disappear from circulation), and let users explore data beyond what the IT department has curated.
Saying one type of BI is better than the other is not accurate. A company may need both types of business intelligence:
Self-Service BI tools provide functional and performance reporting on daily business operations. Also, for questions about the future, especially spur of the moment “what if” style questions, Self-Service BI gives users more individual power and faster reaction times than traditional BI is designed to give.
Traditional BI offers compliance reporting and dashboards, and it can also answer questions about what happened in the past, or about what is happening about operations now.
To showcase the difference between a Self-Service BI and a Traditional BI we’ll explore two solutions offered by Microsoft. In the previous chapter, we’ve discussed MS SQL Server solution, which is a Traditional BI solution. MS also offers Power BI, a Self-Service BI tool. With SQL Server an IT team can develop and deploy a sophisticated DW/BI solution, generate dashboards, reports, Excel embedded reports, Excel Pivot Reports, even Power BI reports, for terabytes of data volumes. The catch here is that the design, implementation and reports generation is performed entirely by the IT staff. Power BI in the other hand allows any user in the business to generate functional reports, connect to data sources with ease, build simple data models and explore small to semi-large data volumes of data with ease. Users can are limited to general reports and insights though, the reason for that is the simple data modelling capabilities Power BI provides. Power BI can handle complex models and generate complex reports and analysis, to do so though, it needs to connect to an OLAP DW designed in an SQL Server.
So when researching a BI tool, if the business, or a department, need real-time answers, a Self-Service BI is the way to go. If your business requires data compliance and complete control of the BI process (extracting, transforming, cleaning, storing and reporting), then a Traditional BI is what your business needs.
The first commercial BI tool we’ll be reviewing is Databox. Databox is one of our favourite BI tools, a tool we keep recommending over and over for individual professionals, startups, small or medium businesses wanting to start implementing insight-driven practices into their business. Databox is extremely easy to implement and use.
Databox is a Self-Service BI solution. Unlike other Self-Service BI solutions in its class, Databox doesn't offer analytics or extensive reporting tools.found in other BI tools, nor doesn’t want to. Instead, Databox focuses on providing Performance BI analytics and has built many innovative solutions for performance analytics.

Performance analytics focuses on providing you with the tools to give you real-time insights into key business metrics and the actions needed to be taken by each team member. Databox embraces performance analytics in every part of the program design and functionality to give you, the business, the best rapid BI workflow to collect data, implement key business metrics and to track performance. To do Databox relies on a big library of data connectors that covers a wide range of cloud applications, from Analytics, Automated Marketing, SEO and SEM, CRM, Social Media, Accounting, E-commerce, App Stores, Video, Database, Project Management and Help Desk.
Databox performance BI leads to one of the fastest BI implementations in the market which allows you to set up a BI solution in a matter of minutes

Connect
Hook up multiple data sources.

Customize
Select key metrics from each.

Access
View all your KPIs everywhere.
Having said that Databox differs from a traditional BI tool in that it doesn’t provide you with functionality to the following:
Data Modeling, you cannot perform any ER or DM of any sort, Databox does provide a strong query builder & calculated metrics
Complex Business Analytics, you can use the Query Builder or SQL for databases that allows you to build simple reports
Data Analytics, you cannot connect or extract the data to pipe-into a data analytics tool or perform analytics on the data.
Drillthrough, you cannot build relations between dashboards, each dashboard and visualisation report works in isolation.
Below are 6 of the top features that we enjoy using Databox for the daily operations of running sales and marketing in our business as well as those of our clients.
Mobile Ready
All BI tools are starting to provide mobile access to the desktop versions of their BI tool. However, none makes it a core design as Databox does. Databox is mobile-focused from the initial stage of designing the dashboard all the way to manage goals, scoreboards and Alert. Accessing key business performance metrics on the mobile is essential if you’re on the go all the time or you need to know if your team is meeting the set KPI’s, and how is the team performance is trending.
Comparisons
All data visualisation types in Databox are set up with the same controls, which makes switching visuals a breeze, one thing that stands in Databox is how easy it is to compare any metric to a variety of useful periods or metrics. Any report or metric built can be compared to the same metric in the previous period (e.g. this week vs last week), or the same period from last year, or to a goal that is either driven by another metric or a scheduled goal that you set.
Query Builder
Databox provides a query interface to most connectors for generating new metrics or interesting reports that can be dropped into any visualisation widget in Databox. The Query Builder is easy to use by anyone in the business so it can be set up in a manner of minutes and have the result available for anyone in the team. If you’re bringing your data through a database connector, then you can use a familiar SQL interface to generate the metrics your business needs.
Calculated Metrics
Ask any business analyst on how easy it is to generate a new calculated metrics, and you’ll know it takes time, perhaps if the source is the same some BI tool makes this process simple, but combining measure from different sources is a time-intensive process that requires data modelling as a start. Databox is the only tool that simplifies the process of generated calculated metrics in a few easy steps that that mimics using a calculator.



Time Based Numeric Goals
Setting up alerts or goals for KPI’s is becoming a standard practice in every BI tool. However, most current implementation covers a linear way of setting alerts, which notifies a person if a KPI value is above or below a certain threshold. Databox offers a whole toolbox for setting goals that easy to create and set against any time series you desire. It also allows scheduling based goal setting that differs from month to month, which is often very complicated to set up in other BI tools.
Templates
If you’re an Agency that provides reports to your client, then you know how complicated it is to build those reports for each client, as it takes the same amount of time to build it for the first client and the nth client. Databox provides a vast library of templates (built by you, Databox or other customers of Databox). Templates allow and Agency to build it once and deploy in minutes to any number of clients in your system without the need to rebuild the reports over and over again.
Databox is suitable for any business department (Marketing or Sales) of varying sizes looking for immediate results to improve key business metrics and is especially appealing for agencies to manage their team performance as well as those for their clients to make sure they are providing the results the business requires. Databox offers a generous and affordable licensing structure that makes it’s accessible for your business as a stand-alone tool or as additional BI tools that sit alongside your main business BI tool.
Target Market: Individual, Start-ups, SMBs and Agencies
Type: Self-Service BI
Departments: Marketing and Sales
Audience: Non-Technical
Price: Free, $49, $99 and $248 for large businesses
Investment Required: Low
Implementation Effort: Low
Implementation Time: Low
URL: https://databox.com
Founded in 2003, Tableau has been the gold standard in data visualisation for a long time. They went public in 2013, thanks to a decade head start, they still probably have the edge on functionality over other BI tools in the market. Tableau dedicated its tools towards data visualisation for years, and results show in several areas: particularly product usability, Tableau’s community, product support, and flexible deployment options, these are a few factors that heavily tip the scales in favour of Tableau.
Tableau offers much more flexibility when it comes to designing your dashboards because of the range of visualisations, user interface layout, visualisation sharing, and intuitive data exploration capabilities. Tableau is hugely customisable in every part of the interface, and the ability to code your visualisation is a point of strength rarely available in other BI tools.
Based on the philosophy of “seeing and exploring” data, Tableau is engineered to create live visual analytics that fuels extensive data exploration. Tableau Interactive dashboards help you uncover hidden insights on the fly. Tableau harnesses people’s natural ability to spot visual patterns quickly, revealing everyday opportunities and eureka moments alike.
Tableau offers a wide range of data analytics functionality to meet the needs of any business analyst requirement. Tableau allows you to quickly build powerful calculations from existing data, drag and drop reference lines and forecasts, and review statistical summaries.
Make your point with trend analyses, regressions, and correlations for tried and true statistical understanding. Ask new questions, spot trends, identify opportunities, and make data-driven decisions with confidence.
When it comes to data connectors, Tableau doesn’t disappoint, as Tableau provides hundreds of data connectors out of the box from on-premise to cloud applications, whether it’s big data, a SQL database, a spreadsheet, or cloud apps like Google Analytics and Salesforce.
- Actian Matrix
- Actian Vector
- Amazon Athena
- Amazon Aurora
- Amazon Elastic MapReduce
- Amazon Redshift
- Anaplan
- Apache Drill
- Aster Database
- Box
- Cisco Information Server
- Cloudera Hadoop Hive
- Cloudera Impala
- DataStax Enterprise
- Denodo
- Dropbox
- ESRI Shapefiles
- Exasol
- Firebird
- GeoJSON
- Google Analytics
- Google BigQuery
- Google Cloud SQL
- Google Sheets
- Hortonworks Hadoop Hive
- HP Vertica
- IBM BigInsights
- IBM DB2
- IBM PDA*
- JSON files
- KML files
- Kognitio
- MapInfo Interchange Formats
- MapInfo Tables
- MapR Hadoop Hive
- Marketo
- MarkLogic
- MemSQL
- Microsoft Access
- Microsoft Analysis Services
- Microsoft Azure Data Lake
- Microsoft Azure Data Warehouse
- Microsoft Azure DB
- Microsoft Excel
- Microsoft OneDrive
- Microsoft PowerPivot
- Microsoft SharePoint Lists
- Microsoft Spark on HDInisght
- Microsoft SQL Server
- Microsoft SQL Server PDW
- MonetDB
- MongoDB
- MongoDB BI
- MySQL
- OData
- Oracle
- Oracle Eloqua
- Oracle Essbase
- PDF files
- Pivotal Greenplum Database
- PostgreSQL
- Presto
- Progress OpenEdge
- Quickbooks Online
- R files
- Salesforce.com, including Force.com and Database.com
- SAP BW
- SAP HANA
- SAP Sybase ASE
- SAP Sybase IQ
- SAS Files
- ServiceNow ITSM
- Snowflake
- Spark SQL
- Splunk
- SPSS Files
- Tableau Data Extract
- Teradata
- Teradata OLAP Connector
- Text files—comma separated value (.csv) files
- Databases and applications that are ODBC 3.0 compliant
- Tons of web data with the Web Data Connector

Tableau offers a built-in powerful ETL engine that allows you to access and combine disparate data without writing code. Power users can pivot, split, and manage metadata to optimise data sources.
Tableau can work with Relational and Cube (OLAP) data sources, in the case of Cube the hierarchies and aggregations need to be created by the cube's designer in advance, this makes Tableau extremely flexible to plug into any organisation existing data warehouse and start analysing the data and produce visualisations. Working with Cube data sources also opens the door to use Multidimensional Expressions (MDX) which allows querying pre-aggregated data. MDX is optimised to query in a statistical way rather than a relational way, with MDX you’re not querying rows and tables to produce a flat result set but you are using tuples and sets to slice and aggregate a multidimensional cube.
Think of it like this: if you use a SQL query to get the total sales amount for a particular item group, you would need to write a query that sums up all invoice lines for all items in the item group. If you are using a cube and have aggregations on the item group level, the result calculates during processing, and the aggregations are stored for each item group, making queries instantaneous.
Tableau is also flexible on how you import your data into Tableau, as it allows you to import (load) the file internally or directly connect to a data source and only query the data you need in real-time using Live Query.
With the addition of Tableau Data Prep solution, Tableau offers your business a one-stop solution for any BI and Business Analytics solution
Beyond all technical factors of data visualisations and business analytics capabilities, Stories is perhaps the one feature that contributed to the vast adaptation success of Tableau in many organisations, as well as setting the standard in future BI tools. All BI tools offer dashboards to provide at a glance insight into the business health and performance, as vital as it is, dashboards lacks narrative, the user is always asked to come up with a narrative based on data data interpretation. Tableau stories create a compelling narrative that empowers everyone you work with to ask their questions. Here are a couple of examples of stories created with Tableau that are web embedded:

Landfall or Close Call: Hurricanes Since 1850
In this visualisation, Mike Cisneros helps us answer questions like: In what parts of the world do hurricanes, or tropical storms pose the greatest danger? How often do the world's largest cities avoid these storms?

Which Gender-Related Policies Should be Prioritised?
Discover how 613 gender advocates from around the world prioritise different issues about gender equality. Created by Andras Szesztai in collaboration with #MakeoverMonday and Equal Measures 2030.

This type of storytelling saw Tableau, and more importantly data, used in all types of industries. The New York Times times began utilising Tableau’s storytelling to provide a compelling narrative in their editorial publications.
Since 2016 Tableau started a significant push into Augmented Analytics in what it calls “Smart Analytics” which saw several acquisitions in the past couple of years, with the latest one being the acquisition of Empirical Systems, an artificial intelligence (AI) startup with an automated discovery and analysis engine designed to spot influencers, key drivers, and exceptions in data. This latest acquisition introduced Hyper in mid-2018, Hyper is Tableau’s new in-memory data engine technology, designed for fast data ingest and analytical query processing on large or complex data sets. Hyper can slice and dice massive volumes of data in seconds, and your business will see up to 5X faster query speed and up to 3X faster extract creation speed. With enhanced extract and query performance, and support for even more massive datasets, you can choose to extract your data based on the needs of your business.
Unfortunately, Tableau comes at a cost. When it comes to the investment required to purchase and implement Tableau. Often, Tableau projects are accompanied by data-warehouse-building endeavours, which compound the amount of money it takes to get going. The results from building a data warehouse and then hooking up Tableau are phenomenal, and you’ll need an implementation budget of $50k at the very least, plus the incremental cost of Tableau licenses.
Also, Tableau is a collection of software and services that work together. A Desktop application performs all data visualisation and BI authoring. The desktop application can publish and share visualisation and reports to other parts of the business through a desktop viewer or an online portal. Using a Desktop application might not be a turn off for some businesses that were hoping for a single cloud application to manage everything.
Be that as it may, Tableau proved that this type of configuration works for many businesses, and if you want the cream of the crop, all other factors aside, Tableau is the choice for you.
Target Market: Start-ups, SMBs and Large Organisations
Type: Self-Service BI
Departments: All department
Audience: Analysts
Price: Starting from $70 per seat.
Investment Required: High
Implementation Effort: High
Implementation Time: High
URL: https://www.tableau.com
Power BI introduced first in 2013 as an Excel-driven product, and later as a standalone service. Since then Power BI quickly gained grounds over Tableau many BI tools in the market. Companies are adopting Power BI a BI and Analytics solution at a faster rate than Tableau, and this is predominantly thanks to rock-bottom cost and fantastic value which starts from Free or a $10 per month pro license that covers all your business needs. Power BI recently started offering a premium on-premise version of Power BI labelled Premium that tailors for larger organisations. This increases adoption of the product as individuals can use Power BI risk-free. For companies that don’t have the budget for a large Business Intelligence project (including a data warehouse, dedicated analysts, and several months of implementation time), Power BI is extremely attractive.
The most significant advantage of Power BI is that it is embedded within the greater Microsoft stack, and quickly becoming more integrated. It’s included in Office 365, and Microsoft encourages the use of Power BI for visualising data from their other cloud services. Power BI is also very capable of connecting to your external business sources. Check this example of how-to build a priority matrix with Power BI.
Power BI offers data preparation, data discovery, interactive dashboards and augmented analytics via a single product. The Gartner report made particular note of Power BI’s low price, ease of use and visual appeal, and was scored highest by customers for “achievement of business benefits”.
When you look at Gartner’s most recent BI Magic Quadrant, you’ll notice that Microsoft is equal to Tableau when it comes to functionality, but strongly outpaces Tableau when it comes to “completeness of vision”.
Power BI is comparable to all of Tableau’s bells and whistles, except for the deeper customisation and power user requirements that you find in Tableau.
Power BI is in an active development cycle. Power BI continuous to release monthly updates that bring new features and functionalities with each release, mostly based on community requests, this puts Power BI ahead of Tableau as most of the design and philosophy of Power BI is to take everything that Tableau offers and make it better while still innovating Power BI own features. This is apparent in all areas of Power BI, from the ability to import new visualisations into Power BI, which unlike Tableau, you don’t need to be a developer and write custom codes, but instead you can choose from hundreds of visualisations from the marketplace and have the visualization ready for use, to giving the user a choice between MDX and DAX (Data Analysis Expressions) to query multidimensional models from Cube data source. The advantage of having DAX is it allows everyone who knows Excel and has been writing expressions and formulas to feel right at home and to start calculating to return one or more values
DAX includes some of the functions used in Excel formulas with additional functions that are designed to work with relational data and perform dynamic aggregation. It is, in part, an evolution of the Multidimensional Expression (MDX) language developed by Microsoft for Analysis Services multidimensional models (often called cubes) combined with Excel formula functions. It is designed to be simple and easy to learn while exposing the power and flexibility of PowerPivot and SSAS (SQL Server Analysis Services) tabular models.
The exciting thing about having the flexibility in using DAX with Power BI is that you can use DAX for both relational and cube data sources. Whereas in Tableau MDX can only be used with cubes and SQL is used for relational data sources.
Just like Tableau, Power BI is a multi-application service, with all data authoring, modelling and design being built on the Desktop while having a cloud version to display and share your reports and dashboards. However, on the plus side for Power BI is that the online portal for Power BI allows users to generate their reports from the cloud without the need to author them in the Desktop (providing all data modelling is done in the Desktop). Having access to such a feature costs $10 monthly per user, as opposed to Tableau that offers a server version (which needs to be hosted by you) which allows minimal customization for the visualisations and subscribe for alerts, which costs $35 monthly per user, or a Tableau View which only allows viewing the data and costs $12 monthly per user. If your organisation would like a hosted SaaS option, then Tableau Server cost $42 per user per month, and Tableau View is $15 per user per month.
Power BI Pro cloud app doesn’t stop with providing with report generation for your data. Power BI cloud connects to many external cloud applications, as well as all of Microsoft stack application, so you can start visualising data and building reports on the cloud. Power BI can even connect directly to your database or data warehouse (if built and hosted on Azure) or import your offline spreadsheets and workbook to start building online dashboards and set up alerts. Perhaps most exciting than those is the ability to connect a real-time data stream (through an API) to display real-time data feeds and visualisation from your applications or IoT devices.
On the augmented analytics side, Power BI is ahead of Tableau in that it provides 3 ways to use Augmented Analytics in Power BI which have been in active development for quite some time.
From the cloud, by exploring the data set to come up with useful insights. It’s a simple method, you right click on a data set and ask Power BI to generate insights, the results are a long list of correlations in your current data sets that you can select and pin to your report or dashboard.
From the desktop by asking “Why”. Perhaps more useful and powerful than the insights version. Why allows an analyst to select any value in visualisation and ask why is this data looking like this? Power BI analyses the data sets and brings in a pop-up that provides you with detailed analysis why this value is looking the way it is.
Visual R Scripts, which allows you write your R scripts from inside of Power BI as another visualisation. Having access to R inside of Power BI allows Data Analysts and Scientist to write complex predictive models and machine learning algorithms all from within Power BI and without the need to have an R Studio or an R Server.
Power BI does have some shortcomings. Based on the active development those issues might be resolved by the time finish reading this guide. The biggest shortcoming is with data processing. Power BI, as with Tableau, you can import your data set into Power BI, which loads the full data set into Power BI memory (Free version have a limit of 1 GB file, while the Pro version goes to 10 GB). You can use Power BI DirectQuery to connect directly to a data source without importing it locally. Unlike Tableau though, DirectQuery limits the number of rows you can query to a million row, which can affect how you're displaying your data or if you need to visualise data larger than a million row. One example where this could be a problem is visualising a path to purchase for a store, as a 1 million row displays only a subset of the entire path.
Another limitation of Power BI is that OLAP support is limited to MS SQL Server databases, which is a deal breaker if your company uses Oracle Essbase, Teradata OLAP, or Analytical Views in SAP Hana as a DW.
At the moment Power BI Desktop is a Windows application. There are no publicised plans to port it to Mac. Also, most current data connectors support the complete Microsoft Stack. So if a business runs on AWS, IBM or Oracle, an additional investment is required to connect to all of the tools the business use, or the business might be forced to migrate to an MS stack to make the most of Power BI, in both cases it is an additional cost to take into account.
Power BI allows 3rd party vendors to build data connectors to popular external cloud applications and distribute them as a complete package (a package includes the server app, SQL database, SSIS, SSAS and the Power BI reports). Packaging connectors this way makes the connectivity problem less of an issue. It is also very easy to provision an instance of Microsoft Server in the cloud which you can deploy Microsoft Power BI on easily which is more cost effective than purchasing a windows machine.
If the choice is between Power BI and Tableau for your business, then Power BI might feel better for Dashboards and visualisations, while Tableau is best used as ad-hoc analysis to work alongside a BI Tool. So if your business is coming from an Excel reporting practice then migrating to Power BI is the simplest and fastest way to get a powerful BI and Data Analytics solution.
Target Market: Start-ups, SMBs and Large Organisations
Type: Self-Service BI
Departments: All department
Audience: Regular business users and Data Analysts
Price: Starting from Free.
Investment Required: Low
Implementation Effort: Low
Implementation Time: Low
URL: https://powerbi.microsoft.com
Birst provides an end-to-end cloud platform for analytics and BI and data management on a multi-tenant architecture. The Birst platform can be deployed on a public or private cloud, or on an appliance (Birst Virtual Appliance). The platform allows customers to choose their data warehouse for the analytics schema, such as SAP HANA, Amazon Redshift, Exasol, and SQL Server.
What this means to your business is that Birst is a one-stop shop, it includes:
Birst comes with its Data Warehouse and ETL tools. Which means you don’t need to build, design and implement a data warehouse, or design a data model for your data using an external application. Birst follows Kimball methodologies for dimensional modelling and OLAP DW.
Birst ships with an internal SQL and MDX language that is used interchangeably for multidimensional data queries and relational data called Birst Query Language (BQL)
BQL can also feature complex scripting that allows you to extend the data modelling to include complex calculations.
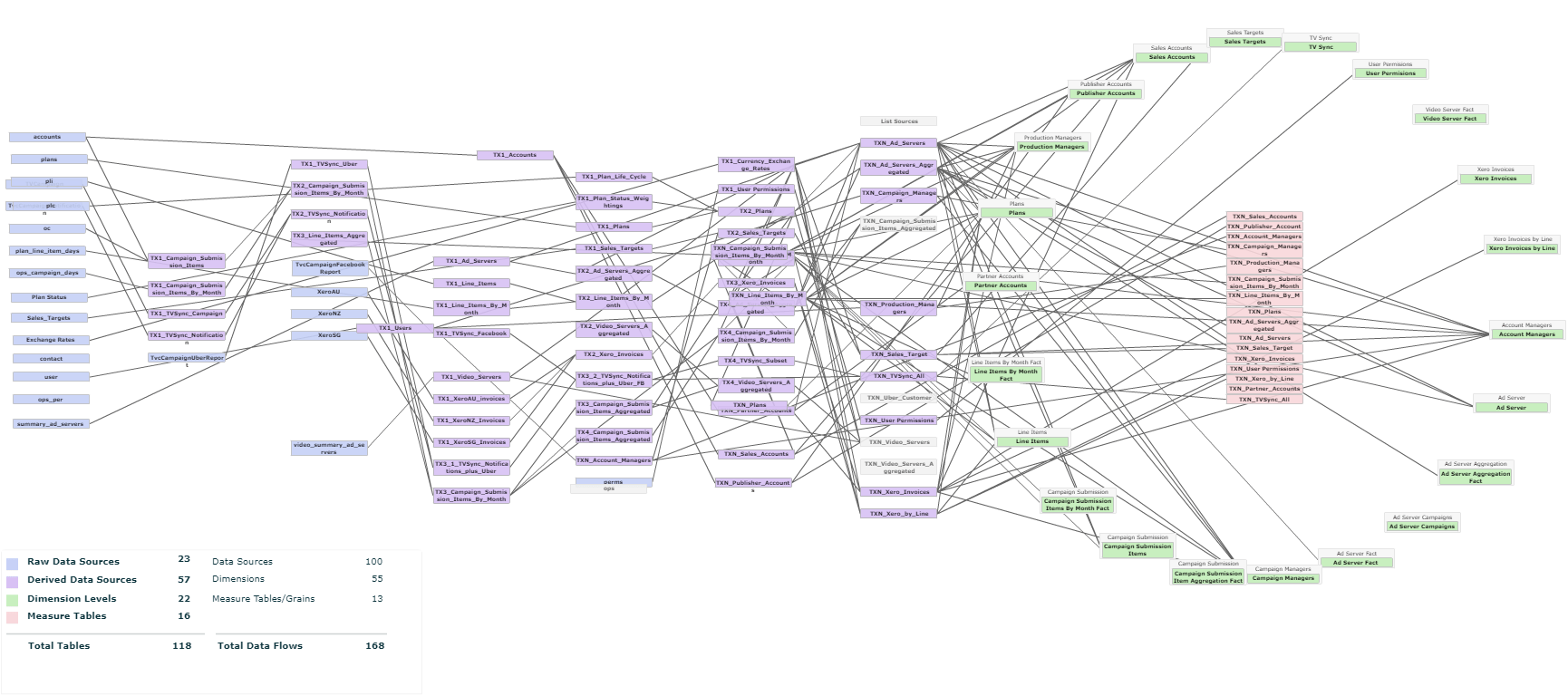
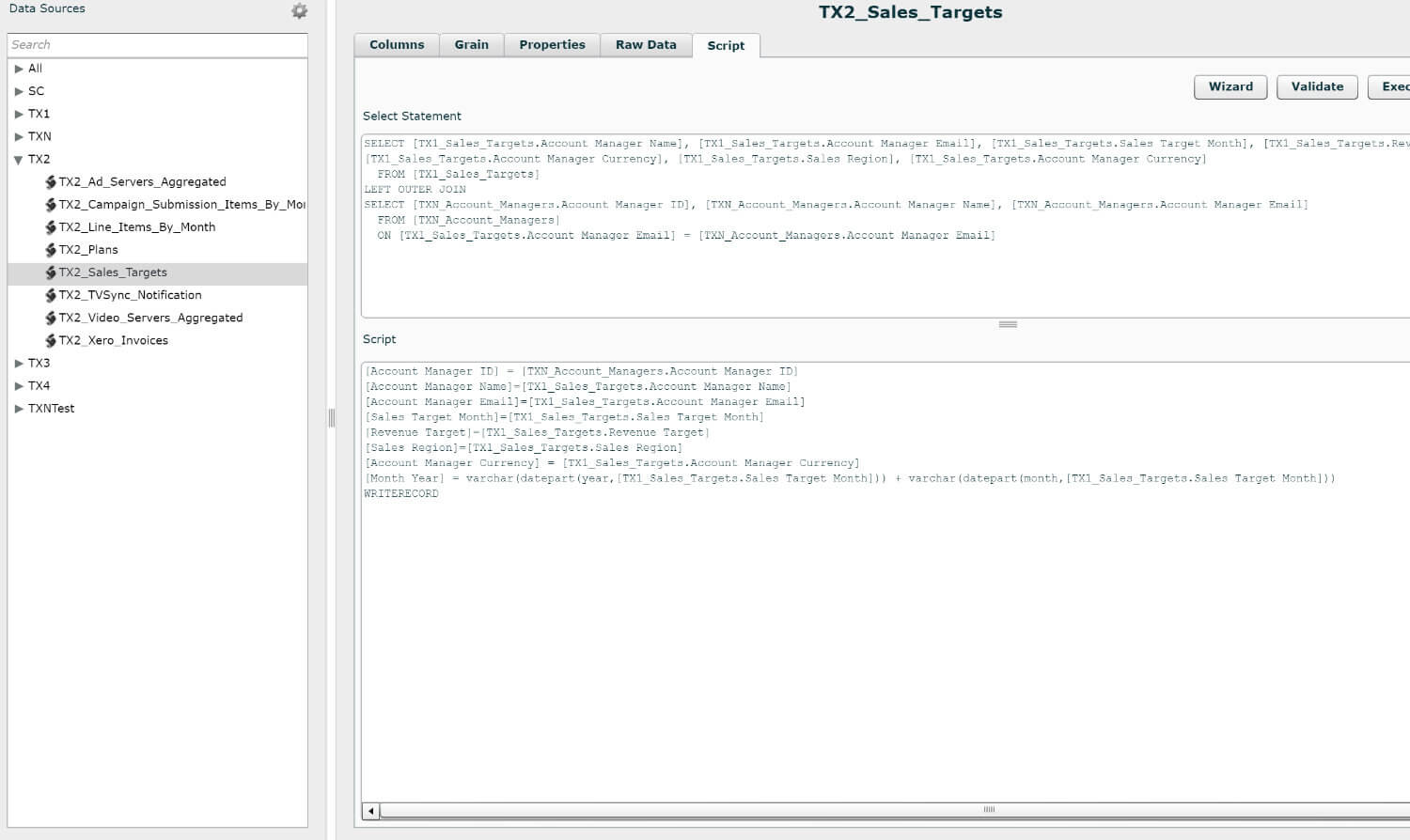
Birst includes a powerful visualiser that allows for various visualisation types and data analysis.
Birst is the only enterprise business intelligence platform that connects the entire organisation through a network of interwoven virtualised BI instances on-top a shared common analytical fabric. Birst creates a set of interwoven analytics and BI instances that share a common data-as-a-service fabric. Networked BI enables organisations to expand the use of BI across multiple regions, product lines, departments and customers in a more agile way and empowers these decentralised teams to augment their enterprise data with their local data.
Networked BI is different, allowing both top-down and bottom-up blending of data. The result is local execution with global governance, eliminating data silos once and for all and dramatically accelerating the delivery of BI across the enterprise.
Top Down: from IT to end users
Enable a central team to expand the use of analytics and BI across the enterprise by creating virtual instances that unify global, local data and metadata.
Bottom Up: from end users to IT
Empower individual end users to access and blend their data with IT-owned data. The blended data can be promoted up to become part of a global business model which maintains governance and ensures people are working with a trusted, consistent source of information.
Birst’s platform strength is in enabling a wide range of analytical needs across both centralised and decentralised analytics. Birst supports everything from data preparation to dashboards to scheduled, formatted report distribution.
Birst standard licensing begins at a$150,000 annually.
Target Market: Medium Businesses and Enterprises
Type: Traditional BI
Departments: All department
Audience: Business and Data Analysts
Price: $100,000+ yearly
Investment Required: High
Implementation Effort: High
Implementation Time: High
URL: https://www.birst.com/
Salesforce is the global CRM leader that offers a suite of platform-connected SaaS products and application development toolkits, allowing businesses to fulfil a wide range of operational and customer engagement requirements. The real strength of Salesforce is the seamless integration of both it's CRM platform along with the Business Intelligence platform to provide contextual reporting, insights and predictability to the user records.
Einstein Analytics Platform
Salesforce Einstein Analytics Platform allows for building analytics apps for any business need, helping every user instantly understand all of the company’s data, spotting patterns, identifying trends, getting inspired, sharing insights, and taking action on any device. It unlocks the full power of data from Salesforce legacy systems, third-party sources, and even products or weblogs.
Salesforce Analytics includes necessary operational reports and dashboards for Salesforce data. A data preparation layer and reporting building and distribution. The Einstein Analytics Platform is for creating point-and-click interactive visualisations, dashboards and analysis with integrated self-service data preparation for Salesforce and non-Salesforce data.
Einstein Analytics integrates natively with Salesforce security, collaboration and metadata, including simplified access to Salesforce application tables through an intuitive wizard. Einstein Analytics also supports extensive usage monitoring across Salesforce products as well as auto geocoding and custom maps for Salesforce data. Users can invoke Salesforce actions from within Einstein Analytics (such as data quality, new campaigns and targeted outreach) and can collaborate using Chatter.




Einstein Discovery - Analyst
Einstein Discovery is an augmented analytics platform based on Salesforce's acquisition of BeyondCore in 2016. It leverages machine learning to generate smart suggestions for how to prepare data, and then automatically finds, visualises and narrates important insights in a story for each user, without requiring them to build models or write algorithms.
Built into the Salesforce Platform, Einstein Discovery is an Augmented Analytics solution that offers AI and Machine learning that delivers discovery, descriptions, and recommendations based on your unique business processes and customer data. It also allows the end user to set specific outcomes against any combination of internal/external data points, and Einstein would then solve or work towards those specific outcomes.
Einstein Discovery is an optional model that is sold as an added component to Einstein Analytics Platform and is priced and provisioned on an account basis rather than on a seat-by-seat basis. The table below provides the typical price to provision Einstein Discovery along with an indicative discount Salesforce might provide.


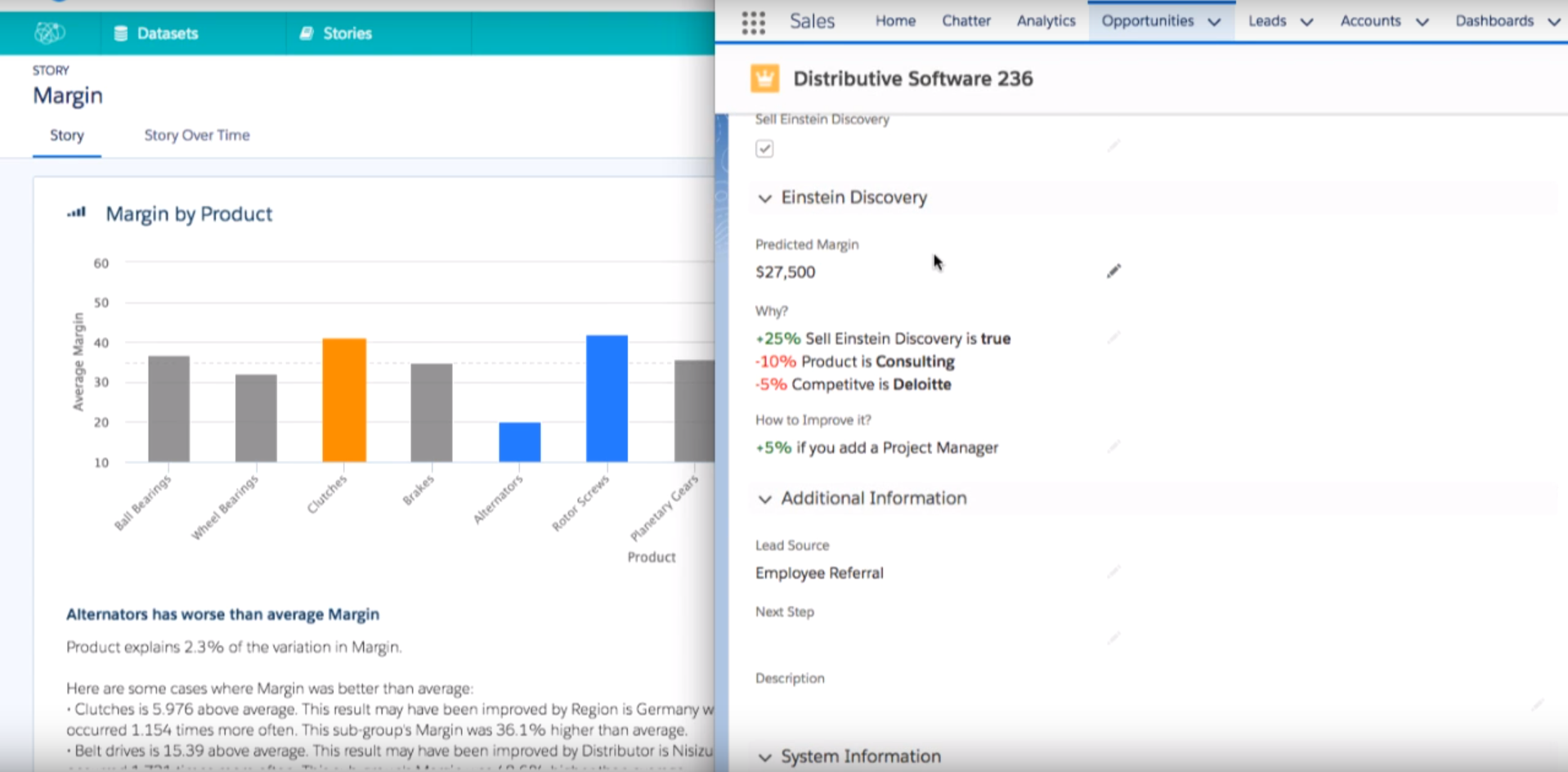

Einstein Analytics can consume the result of the models and predictive capabilities from the Salesforce Einstein collections of services. For example, a lead score is calculated in Einstein and shared across all Salesforce Clouds including Analytics Cloud. The apps, Sales Analytics and Service Analytics, automatically consume and share predictive capabilities in the out-of-the-box predictive dashboards. Also, more advanced predictive capabilities and visual analysis are included via the Einstein Discovery.
Einstein Discovery helps users analyse millions of unique data combination in minutes, for unbiased answers, explanations and recommendations. Salesforce innovative Smart Data Discovery technology gives you a full range of relevant, predictive, and descriptive analytics, empowering every business user with the capabilities of data science. Einstein Discovery generates narrative text, but unlike other offerings, it explains the story behind the analysis. For example, other narrative solutions will say, “revenue in Sydney is higher by 20%” (which only describes the graph), while Einstein Discovery says “revenue in Sydney is higher because we ran more mobile campaigns in Sydney.” Einstein Discovery explains the why, not just what. Once the analysis is complete, it can then be pushed into Salesforce seamlessly so that you can get recommendations where you work.
There are many things to be excited about with Salesforce Einstein suite, from the tight integration to the world-class Augmented Analytics workflow. What sets Salesforce Einstein apart from the rest of the DW/BI solutions is the fact that it’s built on top of Hadoop. Which means Salesforce Einstein is built on top of a Big-Data engine.
“Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.”
The advantages of building on top Hadoop are already apparent in Salesforce Einstein. Analysing millions of rows is faster than most BI solutions in the market, generating dashboards and reports takes seconds to refresh and display. Einstein allows for Natural Langauge Processing (NLP) inside Einstein. Also, all of the prediction and discovery models generated with Discovery can be exported as a native MapReduce Java code or R Code to embed into any application. Salesforce is still scratching the surface of what Einstein delivers, with future releases expect to see more and more AI and Machine learning workflows and capabilities right within the CRM.
Target Market: Medium Businesses and Enterprises
Type: Self-Service BI
Departments: All department
Audience: Business and Data Analysts
Price: Starting from $50 per user per month
Investment Required: Medium
Implementation Effort: Easy
Implementation Time: Easy
URL: https://www.salesforce.com/

Gartner Magic Quadrant in Analytics and BI Platform 2018 Report
Modern analytics and business intelligence platforms represent mainstream buying, with deployments increasingly cloud-based. Data and analytics leaders are upgrading traditional solutions as well as expanding portfolios with new vendors as the market innovates on ease of use and augmented analytics.
Each year, Gartner releases a Magic Quadrant for the Analytics and Business Intelligence Platform space. This Magic Quadrant focuses on products that meet the criteria of a modern analytics and BI platform.
The report is based of market research that rely on proprietary qualitative data analysis methods to demonstrate market trends, such as direction, maturity and participants.
Want to learn more?
Get your complimentary copy here.
There's never been a more exciting time for Business Intelligence than it is now. Over the past 10 years, there have been many BI solutions in the market for every business type or size, from the individuals, startup, SMBe to large enterprises. With pricing ranging from FREE, or $600 to nearly $500,000 annually
However accessible BI has become, most businesses are still on the fence in adopting an insight-driven approach to operate their business and drive it forward. Even though data is at an abundance, and almost all companies utilise digital technologies, cloud and social media to operate and run their business. Hidden pricing is the number 1 attributed cause for this slow adoption. However, rather than labelling these prices as hidden, consider that it's a simple case of knowledge. Knowledge of how data is collected, extracted, modelled and reported.
People are usually drawn to the best and most expensive as a way to distinguish the worth of something, as such an expensive BI tool that cost $500,000 is deemed the best, if a business cannot cover that investment, then BI is placed on the back burner until a time when the business can. On the other hand, FREE or $600 a deemed a gimmick at best, and most don't place any expectations on the value these tools can provide.
BI offers structure, insights and a path to growth, even if it's in a simple implementation form. Getting your business in the cycle of measurement and continuous improvement is the way forward. We wrote The guide with the sole purpose of empowering you with the knowledge to choose a BI solution that works for business today. To know what a little investment brings you, and what a bigger investment entails.
There is a solution for every business need and to fit any budget, the rest is up to you.
We’re stocked to have you here. If you’ve read and enjoyed this guide, we would love to hear from you. If you think this guide can be improved further, or simply want to chat, we would love to hear from you as well. email using our contact page with your ideas..
© 2018 IRONIC3D PTY LTD, i3D. All rights reserved. IRONIC3D is a registered trademark of IRONIC3D PTY LTD, i3D. This publication may not be reproduced or distributed in any form without IRONIC3D’s prior written permission. It consists of the opinions of IRONIC3D's consulting and research, which should not be construed as statements of fact. While the information contained in this publication has been obtained from personal experience and sources believed to be reliable, IRONIC3D disclaims all warranties as to the accuracy, completeness or adequacy of such information. Although IRONIC3D research may address legal and financial issues, IRONIC3D does not provide legal or investment advice and its research should not be construed or used as such. Your access and use of this publication are governed by IRONIC3D’s Usage Policy.